
1 - Controllable Symbolic Music Generation
Attributes-Aware Deep Music Transformation
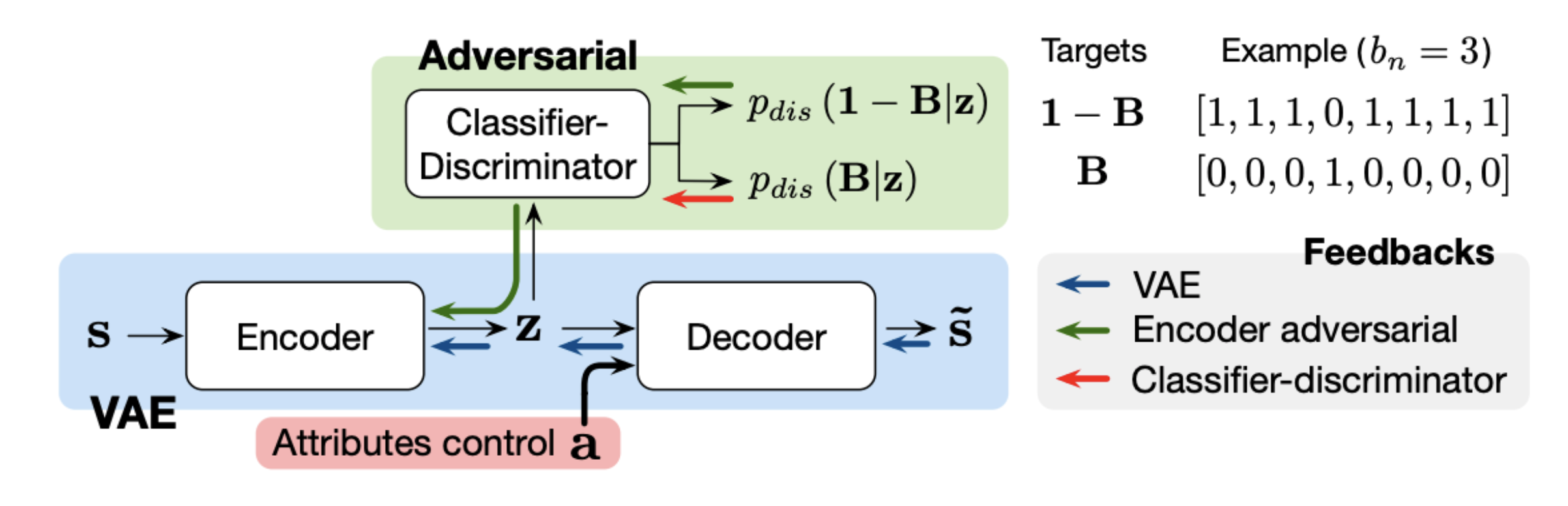
This work uses a very similar architecture like Fader Networks in the computer vision domain - a conditional VAE, with an additional adversarial component to ensure latent \(z\) does not incorporate condition information. Evaluation on controllability is done on monophonic music. I tried the same architecture on polyphonic music in Music FaderNets, but I found that it does not produce optimal results in terms of linearity as compared to other latent regularization methods.
One interesting thing is that the authors do not compare results on linear correlation with GLSR-VAE, because they argued that GLSR-VAE is not designed to enforce linear correlation between latent values and attributes. I agree this to a certain extent, but to me linear correlation between both is still the most intuitive way to achieve controllability on low-level attributes, hence measuring that is still important in the context of controllable generation.
BebopNet: Deep Neural Models for Personalized Jazz Improvisations (Best Paper Award)
Congrats on this paper getting the best research award of this year! Compared to other similar works, this work focuses on personalization. Within the pipeline, other than the generation component, a dataset personal to the user is collected to train personal preference metrics, very much like an active learning strategy. As the music plays, the user adjusts a meter to display the level of satisfaction of the currently heard jazz solo. Then a regression model is trained to predict the user’s taste. Finally, a beam serach is employed by using the criterion of score predicted the user preference regression model. The output of beam search should result in a music piece most adhered to the user preference. A very simple idea, but could be widely adoptable to all kinds of generation models to add in more degree of personalization.
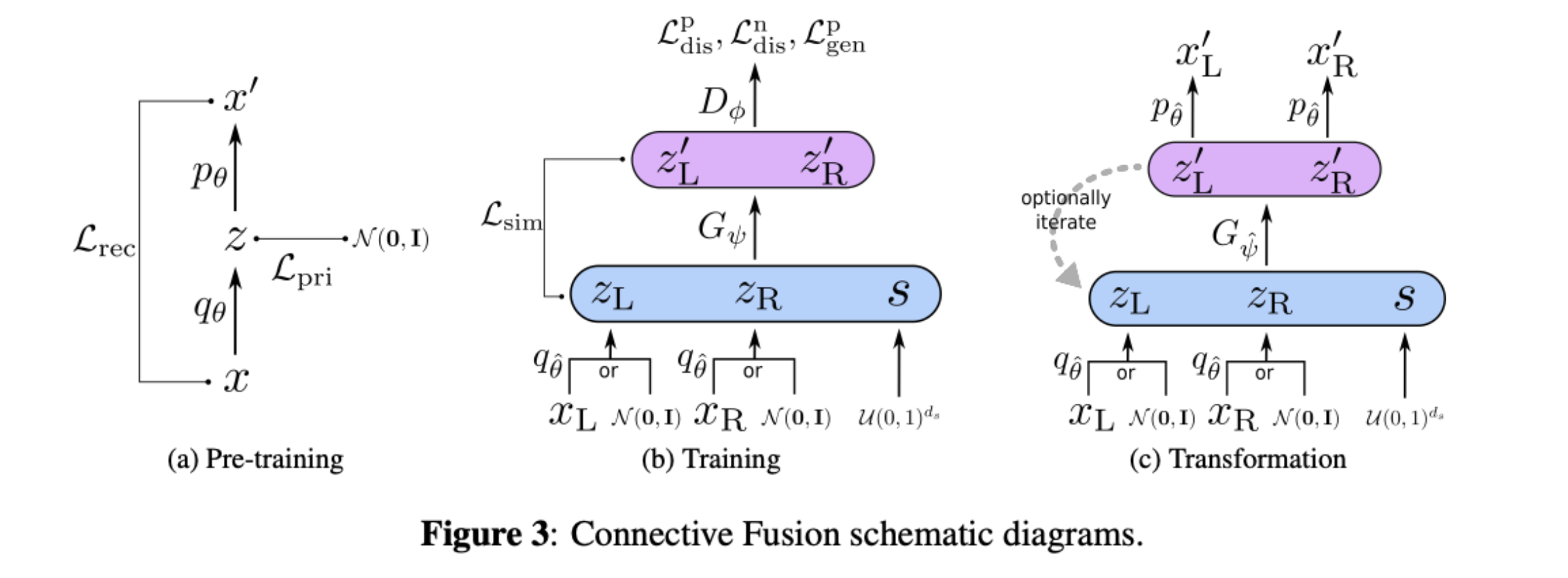
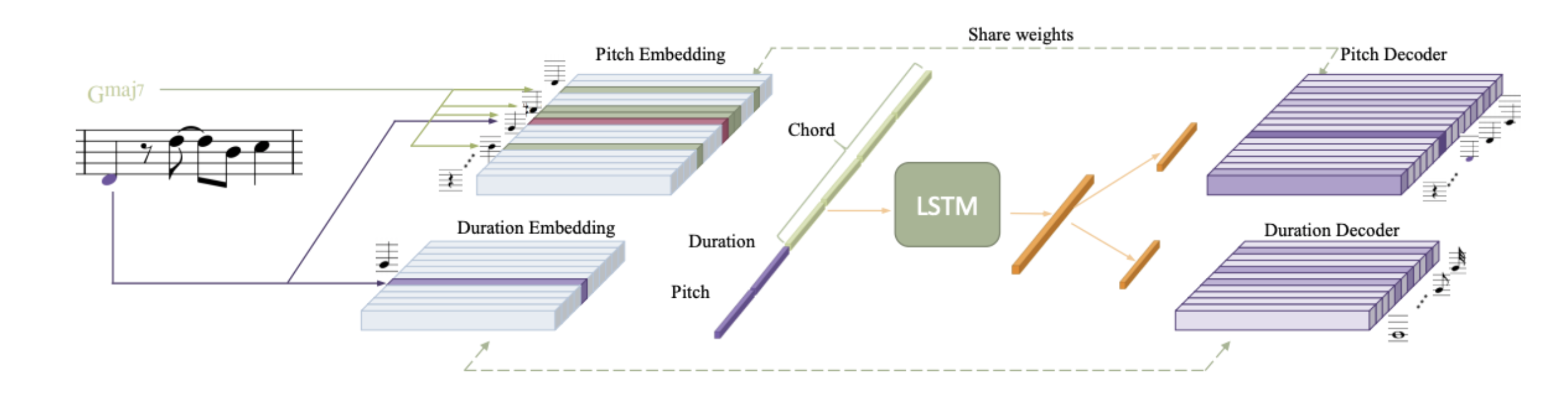
This work proposes connective fusion, which is a generation scheme by transforming between two given music sequences. The architecture is inspired by the Latent Constraint paper - firstly, we pretrain a VAE to learn latent code \(z\) for a music sequence. Then, using a GAN-like actor-critic method, we learn a generator \(G\) that generates latent code pair \((z^\prime_L, z^\prime_R)\) that is indistuingishable from the input pair\((z_L, z_R)\). During training, we also add in an additional style vector \(s\), hence also learning a style space which controls how the two sequences are connectively fused.
I was fortunate enough to discuss with the author Taketo Akama about several issues of using VAE for music generation. In general, we found a significant tradeoff between attribute controllability and reconstruction (identity preservation), and training to generate longer sequence seems to really be a hassle. His work last year has also helped me a lot with Music FaderNets, so huge kudos to him!
Generating Music with a Self-Correcting Non-Chronological Autoregressive Model
I spotted this work previously during ML4MD and find it interesting because it suggests a very different approach towards music generation, which is using edit distance. The two key differences with common music generation idea is that (i) music composition can be non-chronological in nature, and (ii) the generation process should allow adding and removing notes. The input representaion used is pixel-like piano roll, so the approach inherits the problem of not distinguishing long sustains and continuous short onsets. Also, the evaluation is done with comparison against orderless NADE and CoCoNet, but with several recent works suggesting that richer vocabulary of event tokens can improve generation results, it might me interesting to see how this work compares or even adds value on top of these works.
PIANOTREE VAE: Structured Representation Learning for Polyphonic Music
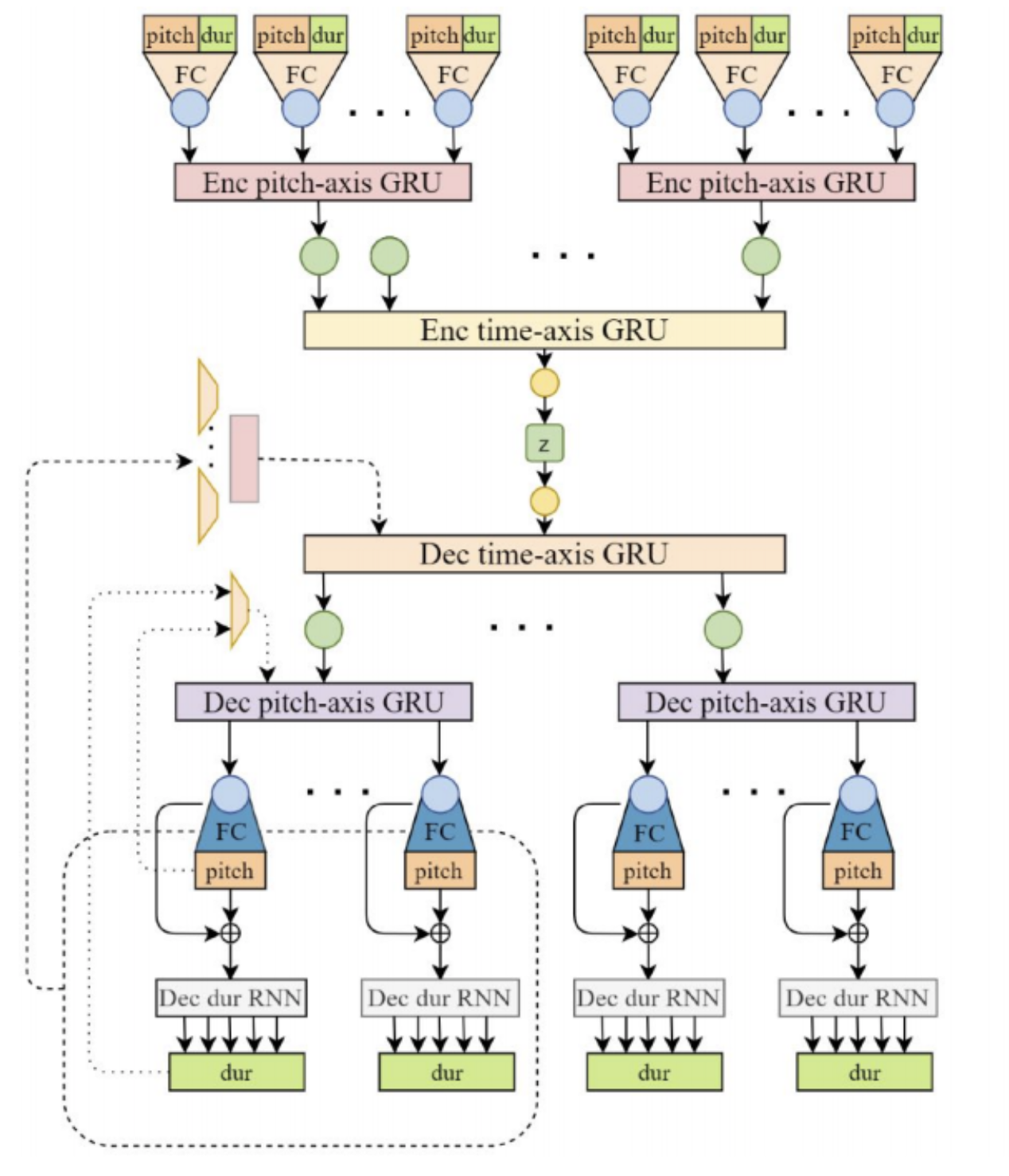
This work proposes a new hierarchical representation for polyphonic music. Commonly, polyphonic music is either represented by piano rolls (which is commonly treated like pixels), or MIDI event tokens. The authors suggest a tree-like structure, where each beat is a tree node, and the notes played on the same beat are the childrens of the node. They also propose a VAE model structure which has one-to-one correspondence with the data structure, and the evaluation shows that as compared to previous representations, PianoTree VAE is superior in terms of reconstruction and downstream music generation.
I definitely think that PianoTree has the potential to be the de facto representation of polyphonic music, because indeed it is more reasonable to understand polyphonic music in terms of hierachical structure, as compared to a flat sequence of tokens. However, I personally think that the common usage of PianoTree will depend on two key factor: the ease of usage (e.g. open source of encoder components and examples of usage), and whether the data structure is tightly coupled with the proposed VAE model. Event tokens are used widespread because any kind of sequence models / NLP models can be ported on top of that representation. Can PianoTree be ported easily to other kinds of architectures, and will the performance on all aspects remain the same? This is a crucial point for whether the structure will replace event tokens and be adopted widely in my opinion.
Learning Interpretable Representation for Controllable Polyphonic Music Generation
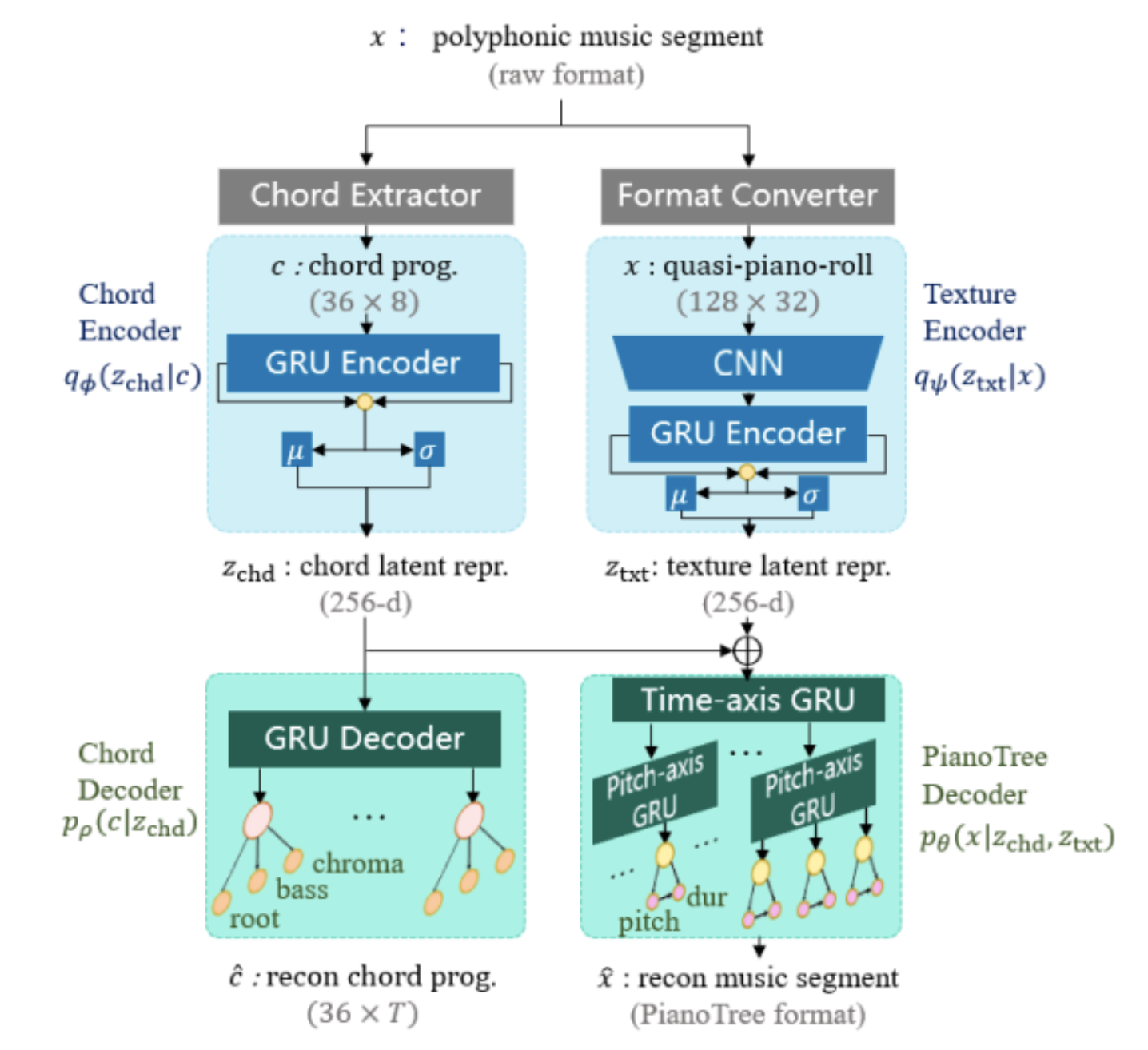
This work is a demonstration of the power of PianoTree VAE above. This time, the authors explore the disentanglement of chords and texture of a music piece. The architecture adopts a similar idea as their prior work called EC\(^2\)-VAE (which inspires Music FaderNets a huge lot as well!), where a chord encoder and texture encoder is used for latent representation learning, and a chord decoder with the PianoTree VAE decoder is used for reconstruction. They evaluated the results on three practical generation tasks: compositional style transfer, texture variation via sampling, and accompaniment arrangement. And, their demo and quality of generation is really superb, so it seems like PianoTree could really work well.
Meeting the NYU Shanghai team has also been a great experience, especially the discussions with Ziyu Wang has been really enjoyable. Huge kudos to them!
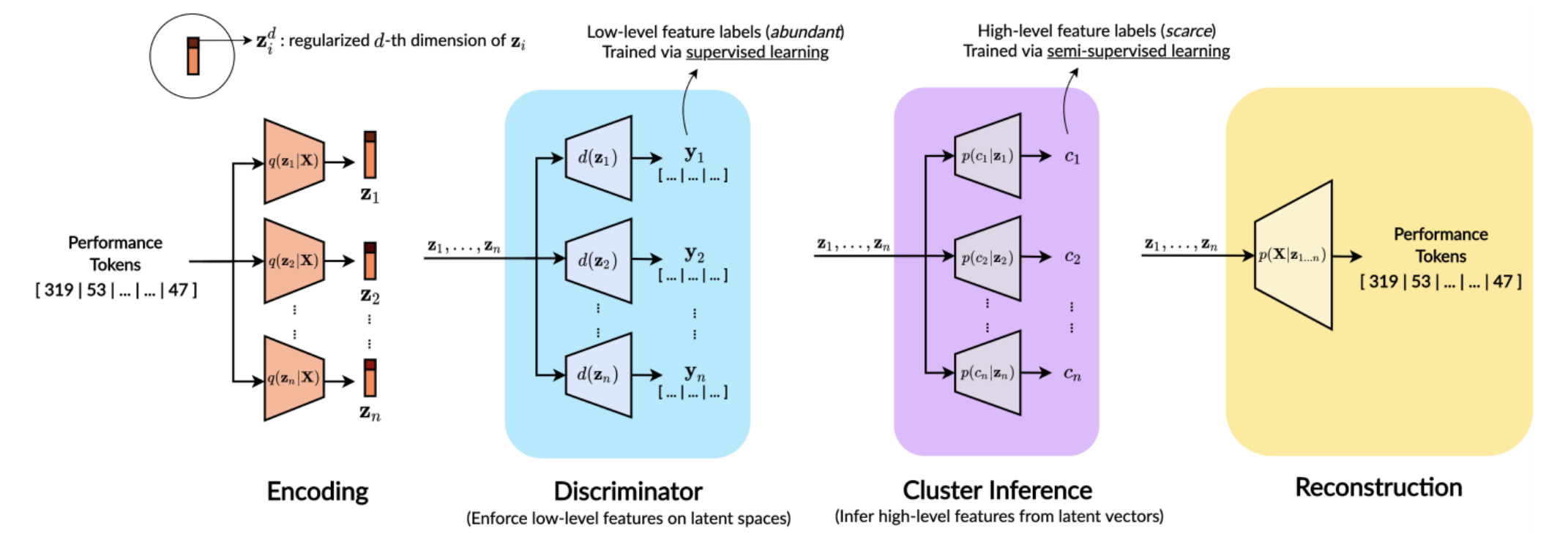
My work on controllable polyphonic music generation! At first I wanted to work on controllable geneeration based on emotion, but I found that representations of high-level musical qualities are not easy to learn with supervised learning techniques, either because of the insufficiency of labels, or the subjectiveness (and hence large variance) in human-annotated labels. We propose to use low-level features as “bridges” to between the music and the high level features. Hence, the model consists of:
- faders, where each fader controls a low-level attribute of the music sample independently in a continuous manner. This relies on latent regularization and feature disentanglement
- presets, which learn the relationship between the levels of the sliding knobs of low-level features, and the selected high-level feature. This relies on Gaussian Mixture VAEs which imposes hierachical dependencies.
This method combines the advantages of rule-based methods and data-driven machine learning. Rule-based systems are good at interpretability (i.e. you can explicitly hear that some factors are obviously changing during generation), but it is not robust to all situations; whereas machine learning methods are the total opposite. Another interesting point is the usage of semi-supervised learning. Since we know that arousal labels are noisy, we can choose only the quality ones with lesser variance and higher representability for training. In this work we prove that lesser labels can be a good thing - using the semi-supervised setting of GM-VAE to train, with only 1% of labelled arousal data, we can learn well-separated, discriminative mixtures. This can provide a feasible approach to learn representations of other kinds of abstract high-level features.
Music SketchNet: Controllable Music Generation via Factorized Representations of Pitch and Rhythm
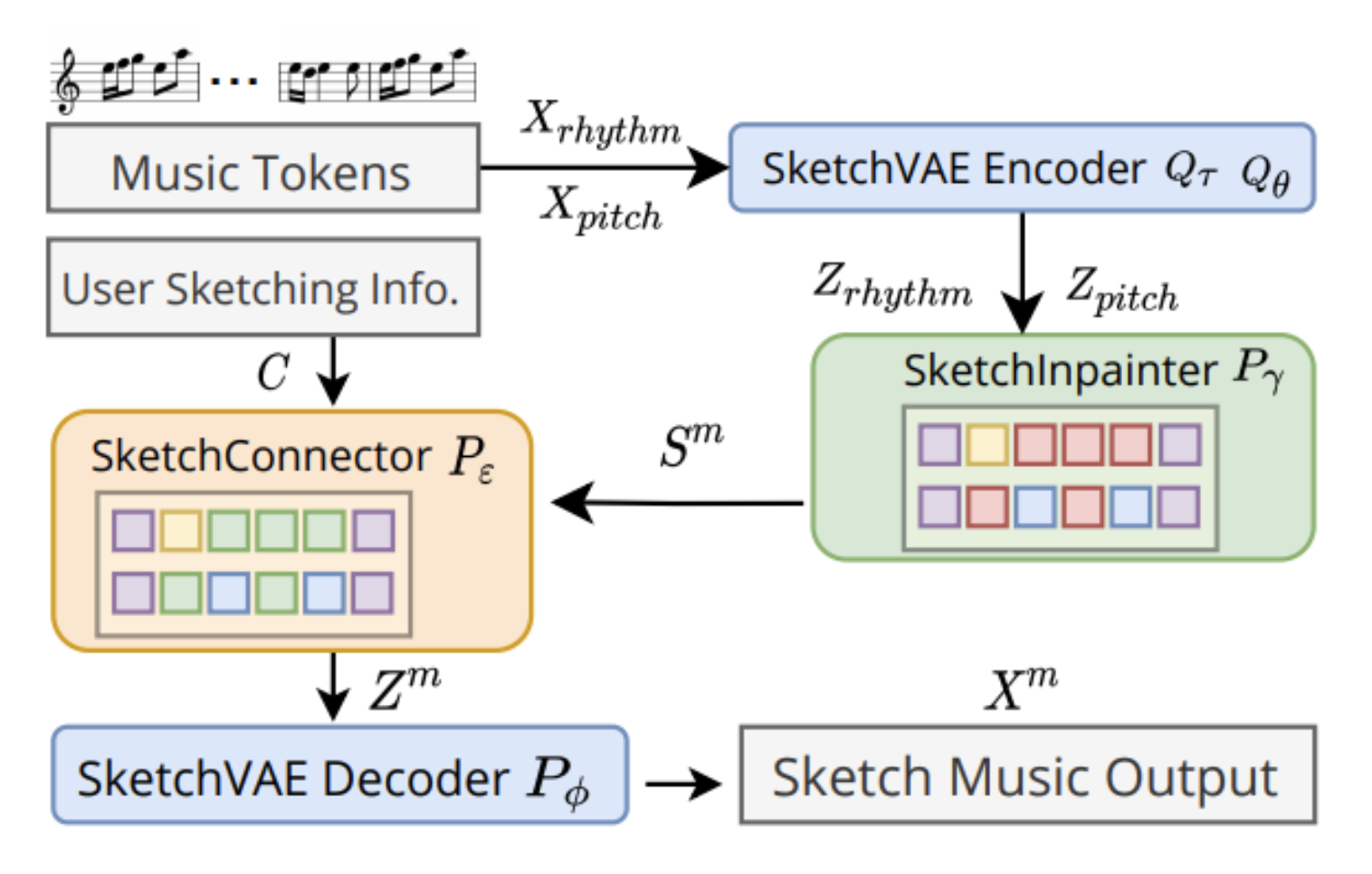
This work explores the application of music inpainting - given partial musical ideas (i.e. music segments), the model is able to “fill up the blanks” with sequences of similar style. An additional controllable factor is provided in this model on pitch and rhythm (pretty much inspired by EC\(^2\)-VAE as well). There are 3 separate components: SketchVAE for latent representation learning, SketchInpainter for predicting missing measures based on previous and future contexts, and SketchConnector which finalizes the generation by simulating user controls with random unmasking (a common technique in training language generators).
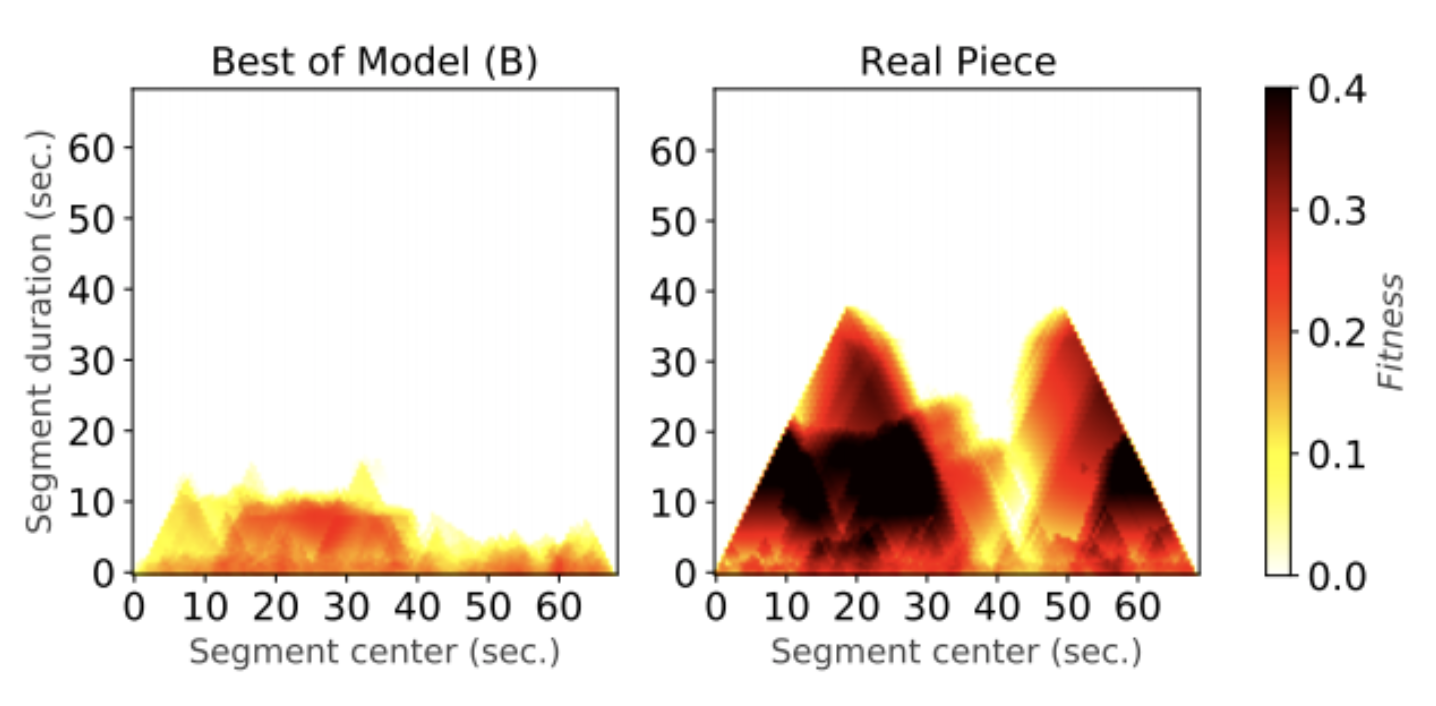
This is a really interesting work that tries to answer a lot of pressing questions related to Transformer-based music generation. Are Transformers really that good? If not, what are the culprits? Does structure-related labels help generation?
For me the real key contributions for this work are the findings concluded on the proposed objective metrics used to evaluate the generated music. There are so many objective metrics being proposed (I recall this work suggesting several metrics for Transformer AE as well), but for Transformers which are often crowned for more structured generation, how do we evaluate structureness other than subjective tests? I find the idea of using fitness scape plot to quantify structureness super interesting. Although the field will never agree on a set of evaluation metrics, but understanding where Transformers are still short of in overall will definitely drive the community to pinpoint on certain areas to improve.
2 - Disentangled Representation Learning
Unsupervised Disentanglement of Pitch and Timbre for Isolated Musical Instrument Sounds
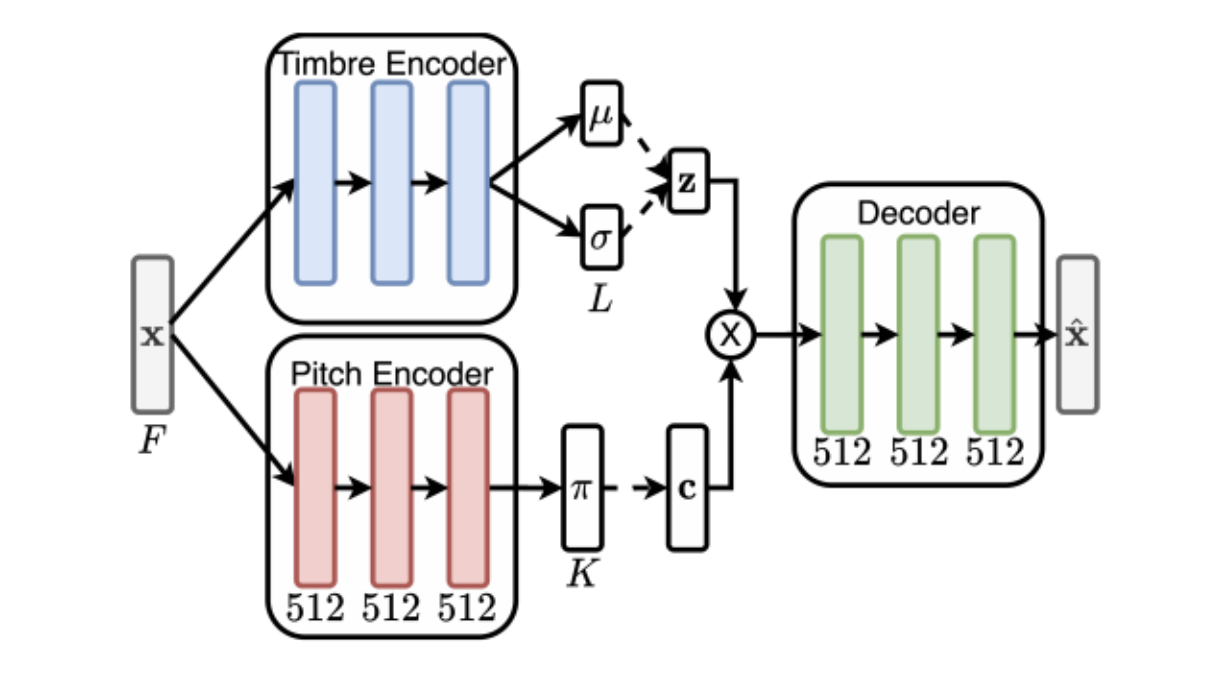
Work by my senpais, Yin-Jyun Luo and and Raven Cheuk, so definitely hands down! Jyun worked on pitch-timbre disentanglement before, and in this work he decided to push it further - can we do such disentanglement in an unsupervised manner?
This work employs a key idea: moderate pitch shiftings will not change timbre. Hence, even if we don’t have any labels annotated on pitch and timbre, we can still achieve disentanglement by contrastive learning paradigms - data augmentation by transposing the pitch, but enforce relations in \(z_\textrm{pitch}\) and \(z_\textrm{timbre}\). The authors propose 4 losses: regression loss, contrastive loss, cycle consistency loss and a new surrogate label loss. I personally think the power of this framework is not just for disentangling timbre and pitch, but unsupervised representation learning as a whole. Can this unsupervised framework be applied on other harder problems (e.g. music sequences, and disentangling musical factors)? How would data augmentation happen in different problems, and would that affect the formulation of losses? These will be interesting questions that require much creativity to explore.
Metric learning VS classification for disentangled music representation learning
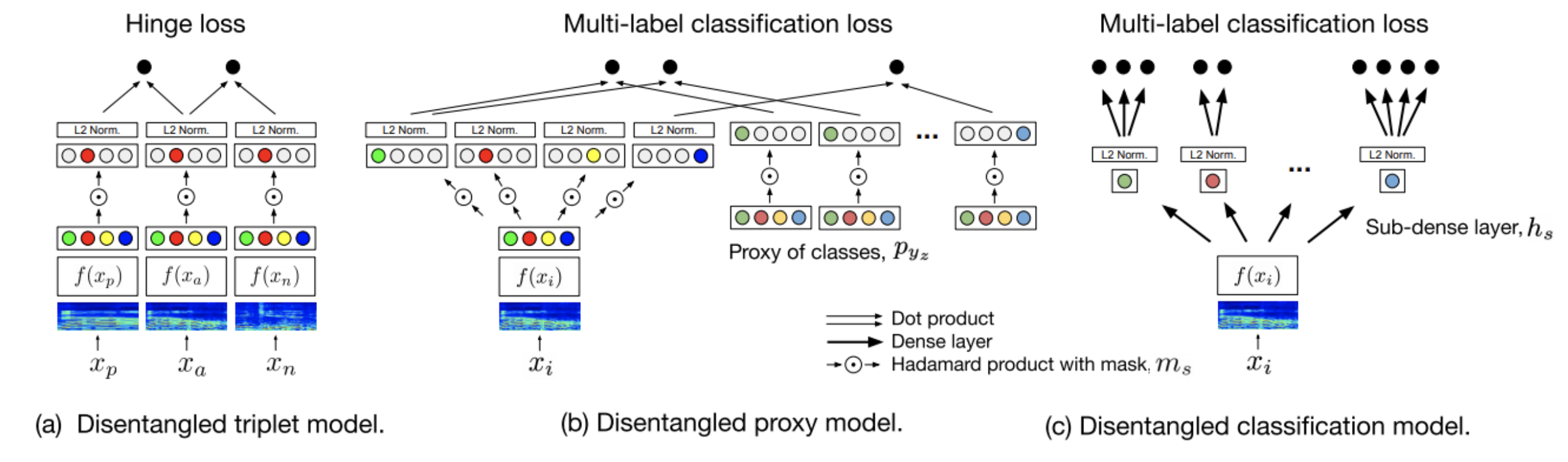
This interesting work connects 3 things together: metric learning (learns similarity between examples), classification, and disentangled representation learning (which corresponds to this work). Firstly, the authors connect classication and metric learning with proxy-based metric learning. Then, with all combinations of models and their disentangled version, evaluation is done on 4 types of tasks: training time, similarity retrieval, auto-tagging, and triplet-prediction. Results show that classification-based models are
generally advantageous for training time, similarity retrieval, and auto-tagging, while deep metric learning exhibits better performance for triplet-prediction. Disentanglement slightly improves the result on most settings.
dMelodies: A Music Dataset for Disentanglement Learning
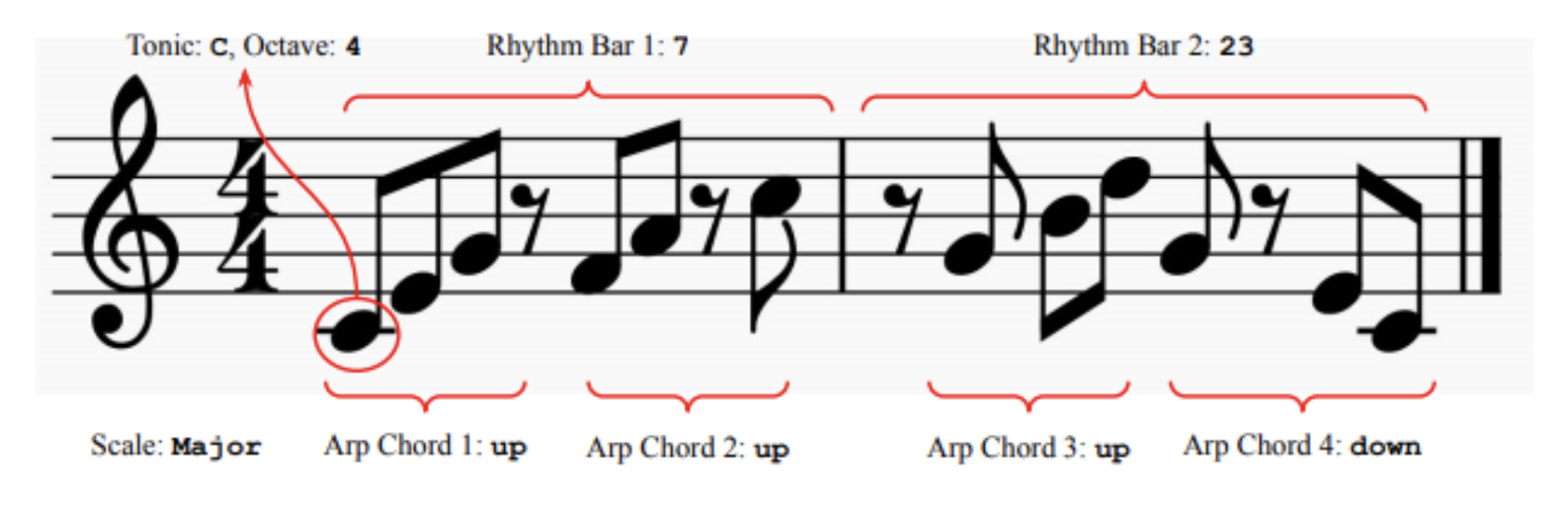
This work proposes a new dataset which resembles dSprites in the computer vision domain, which is designed for learning and evaluating disentangled representation learning algorithms for music. The authors also ran benchmark experiments using common disentanglement methods (\(\beta\)-VAE, Annealed-VAE and Factor-VAE). Overall, the results suggest that disentanglement is comparable, but reconstruction accuracy is much worse, and the sensitivity on hyperparameters are much higher. This again proves the tradeoff between reconstruction and disentanglement / controllability using VAEs on music data.
I discussed with the author Ashis Pati on why not use real-world monophonic music dataset (e.g. Nottingham dataset) with attribute annotations, but generating synthetic data instead. He suggests that it is to preserve the orthogonality and balanced composition of each attribute within the dataset. It seems like the balance between orthogonality and resemblance to real music is a lot more delicate that expected when creating a dataset like this. (Meanwhile, Ashis’ work has been very crucial to Music FaderNets, and it is such a joy to finally meet him and chat in person. One of the coolest moment during the conference!)
3 - Singing Voice Conversion
Zero-Shot Singing Voice Conversion
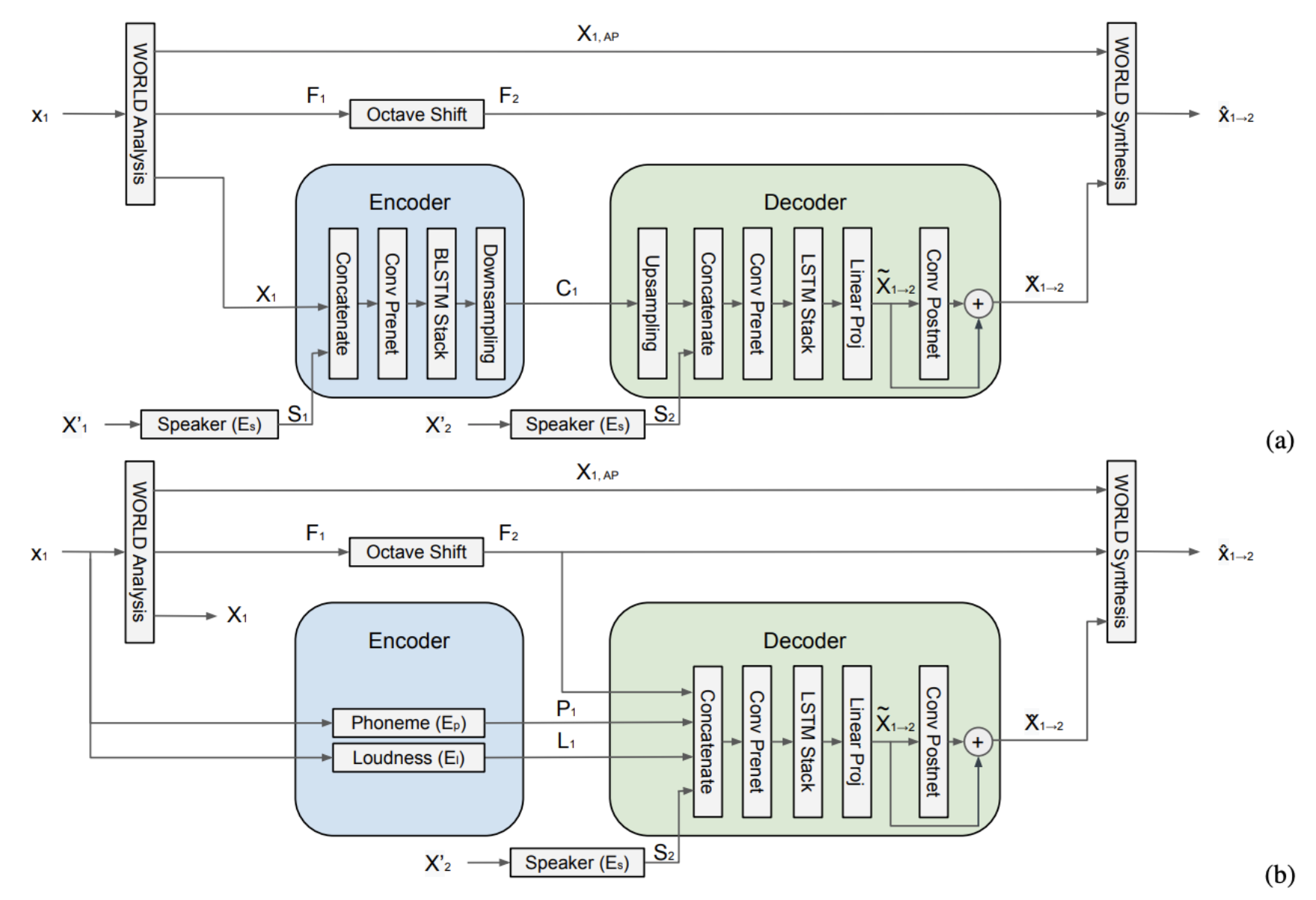
The most interesting part of this work is the zero-shot part, which largely incorporates ideas from the speech domain. Speaker embedding networks were found to be successful for enabling zero-shot voice conversion of speech, whereby the system can model and adapt to new unseen voices on the fly. The authors adopted the same idea for singing voice conversion by using a pretrained speaker embedding network, and then using the WORLD vocoder with learnable parameters for synthesis. It seems like the “pre-trained fine-tune” idea from other domains has influenced much works in MIR, moreover this work shows that using relevant foreign-domain embeddings (speech) on music tasks (singing voice) can actually work.
4 - Audio Synthesis
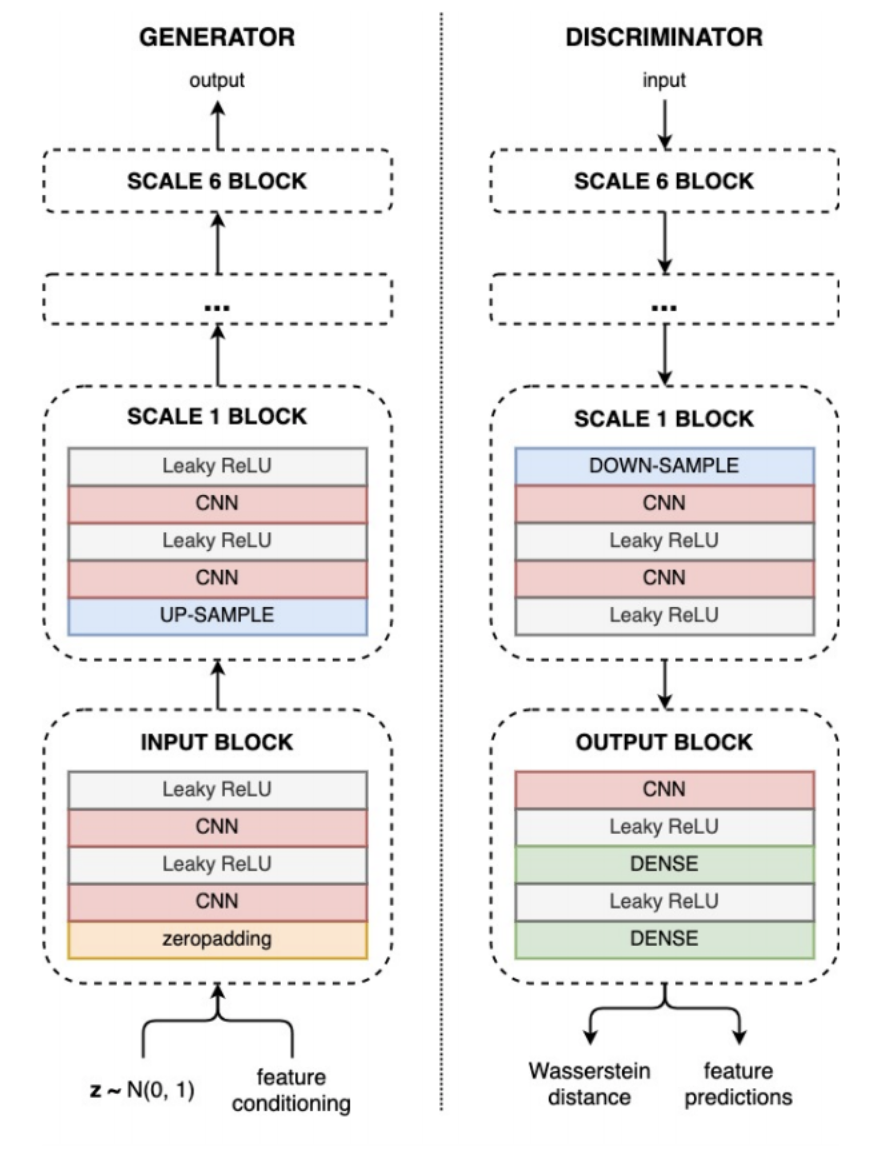
Super cool and useful work (can’t wait to use the plugin as a producer)! This work uses a progressive growing GAN (similar to the idea in GANSynth) to synthesize different types of drum sounds. Moreover, to achieve user controllability, the model allows several factors to be changed during input time, including brightness, boominess, hardness etc. to synthesize different kinds of drum sounds. To evaluate controllability, unlike using Spearman / Pearson correlation or R-score in linear regressor, which are more popular in the music generation domain, this work evaluates against several other baseline scores as proposed in a previous work using U-Net architecture. This could probably shed light to a new spectrum of measurements in terms of factor controllability.
Another interesting thing is that this work uses complex STFT spectrogram as the audio representation. When I worked on piano audio synthesis, the common representation used is the magnitude Mel-spectrogram, which is why for the output a vocoder (e.g. WaveNet, WaveGAN, WaveGlow) is needed to invert Mel-spectrograms to audio. But in this work, the output directly reconstructs the real and imaginary parts of the spectrogram, and to reconstruct the audio we only need to do an inverse STFT. This can ensure better audio reconstruction quality, and phase information might also help audio representation learning.
5 - Music Source Separation
Investigating U-Nets with various Intermediate Blocks for Spectrogram-based Singing Voice Separation
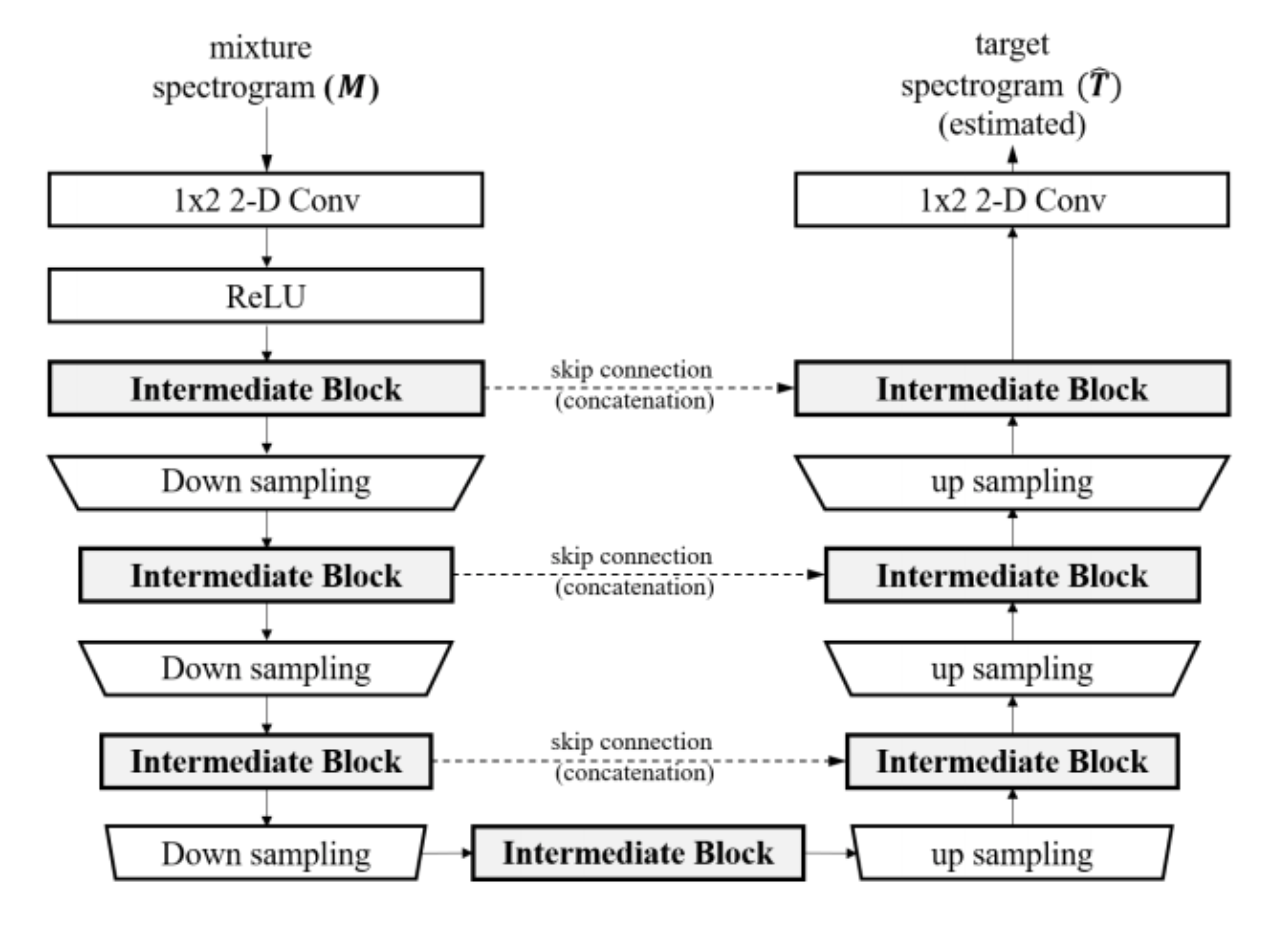
U-Nets are very common in singing voice separation, with their prior success in image segmentation. This work further inspects the usage of various intermediate blocks by providing comparison and evaluations. 2 types of intermediate blocks are used, Time-Distributed Blocks which does not have inter-frame operations, and Time-Frequency Blocks which considers both time and frequency domain. The variants of each block are inspected (fully connected, CNN, RNN etc.). The demo provided by this work is really superb - the best configuration found in this work yields a very clean singing voice separation.
Content based singing voice source separation via strong conditioning using aligned phonemes
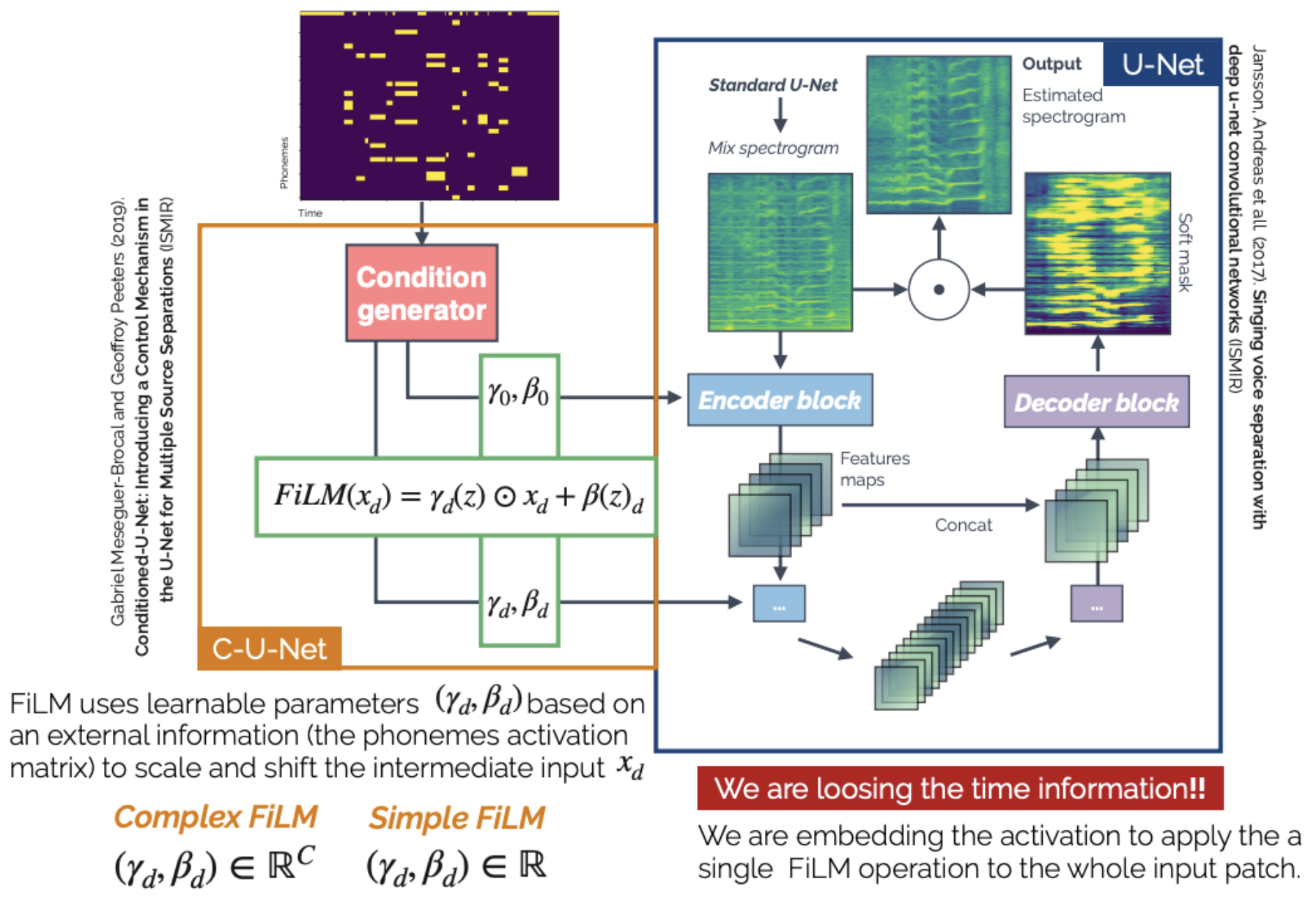
This work explores informed source separation - utilizing prior knowledge about the mixture and target source. In this work, the conditioning information used is lyrics, which are further aligned in the granularity of phonemes. This work uses the FiLM layer for conditioning, which the conditioning input is a 2D matrix of phonemes w.r.t. time. For weak conditioning, the same FiLM operation to the whole input patch; for strong conditioning, different FiLM operations are computed at different time frames.
Exploring Aligned Lyrics-informed Singing Voice Separation
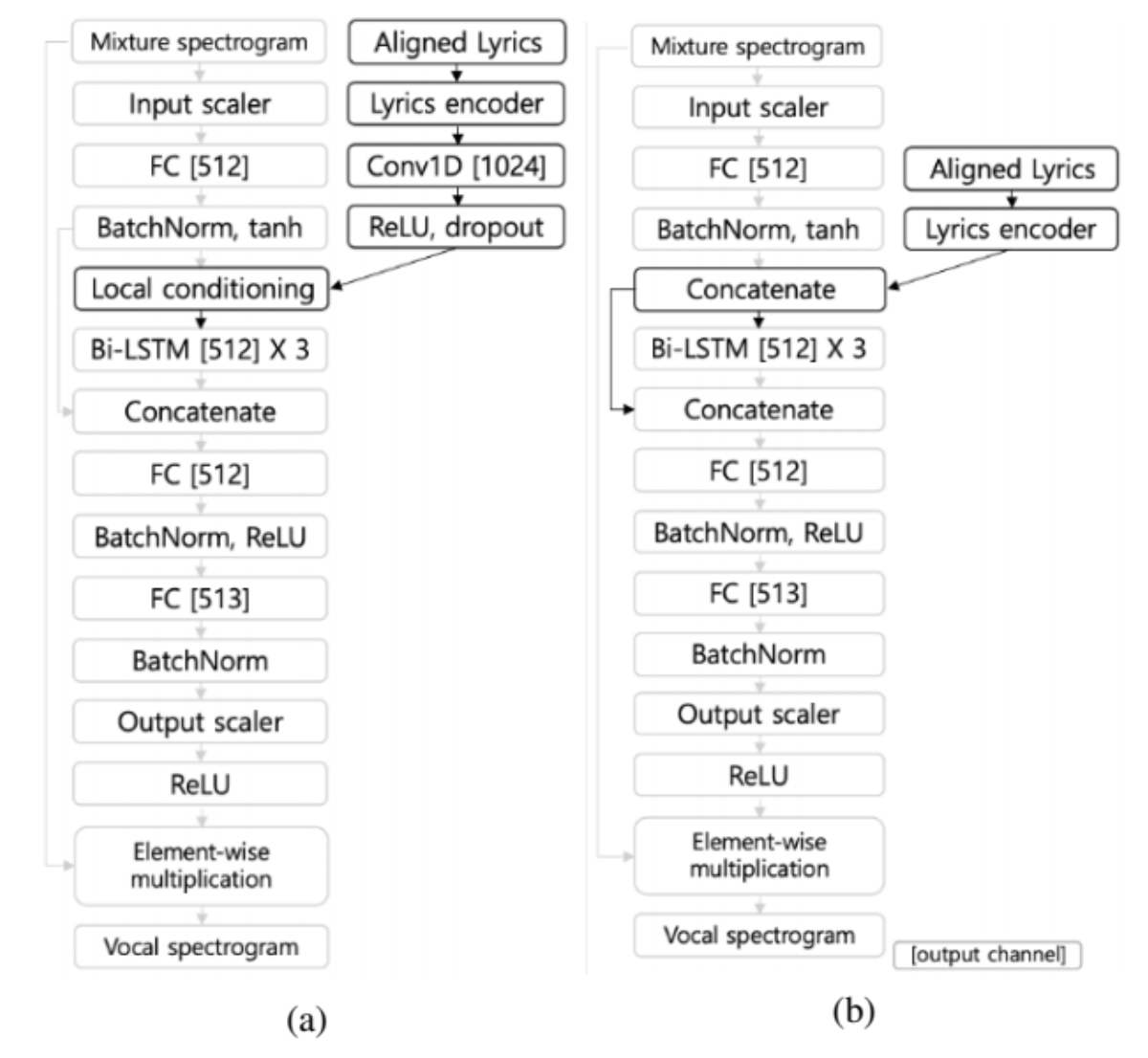
Similar to the above work, this work also utilizes aligned lyrics / phonemes for improving singing voice separation. The architecture is different - this work takes the backbone from the state-of-the-art Open Unmix model, then the authors propose to use an additional lyric encoder to learn embeddings for conditioning on the backbone. This idea resembles much with the idea from text-to-speech models, where the text information is encoded to condition on the speech synthesis component.
Multitask Learning for Instrument Activation Aware Music Source Separation
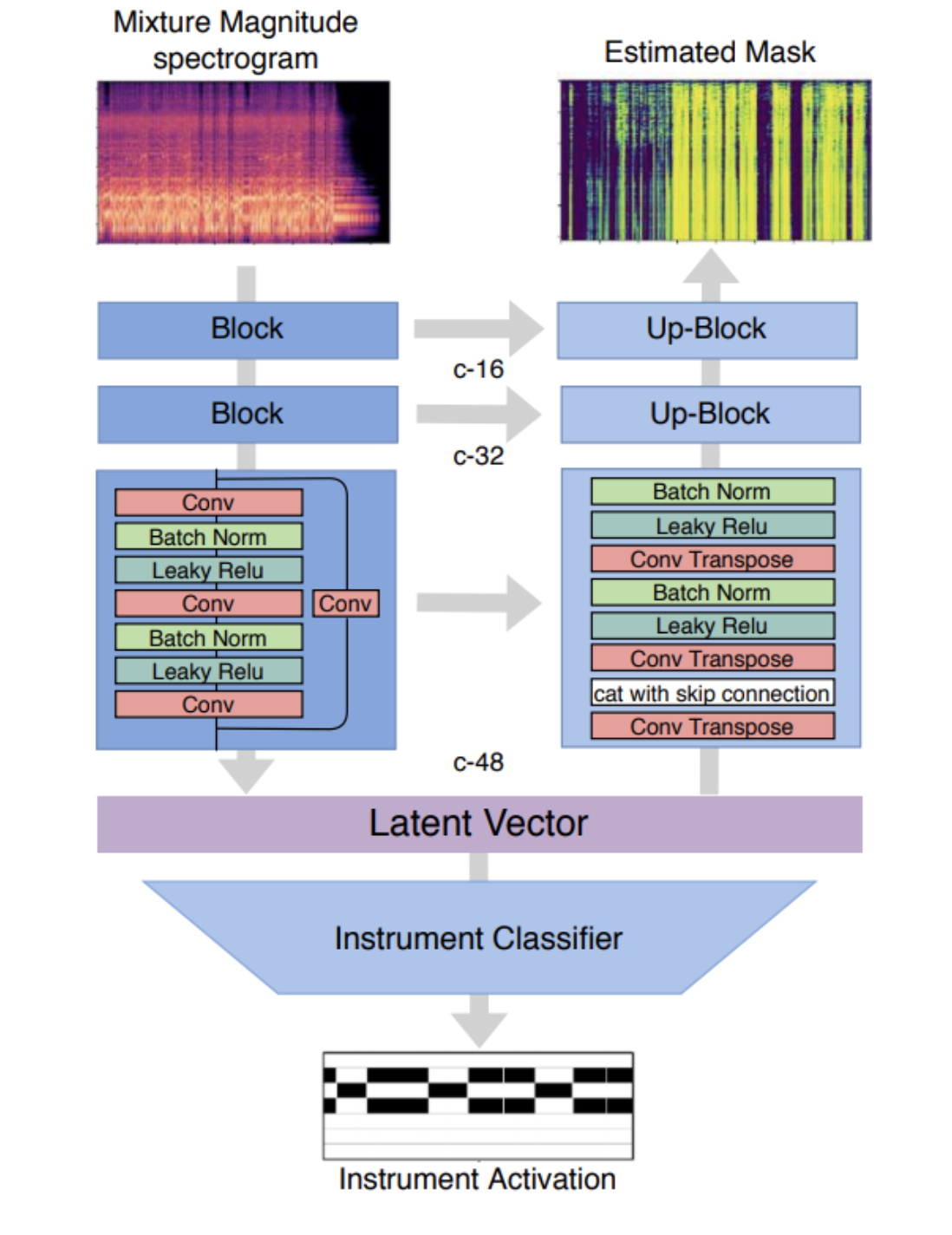
This work leverages multitask learning for source separation. Multitask learning states that by choosing a relevant subsidiary task, and allow it to train in line with the original task, can improve the performance of the original task. This work chooses to use instrument activation detection as the subsidary task, because it can intuitively suppress wrongly predicted activation by the source separation model at the supposed silent segments. By training on a larger dataset with multitask learning, the model can perform better on almost all aspects as compared to Open Unmix.
6 - Music Transcription / Pitch Estimation
Multiple F0 Estimation in Vocal Ensembles using Convolutional Neural Networks
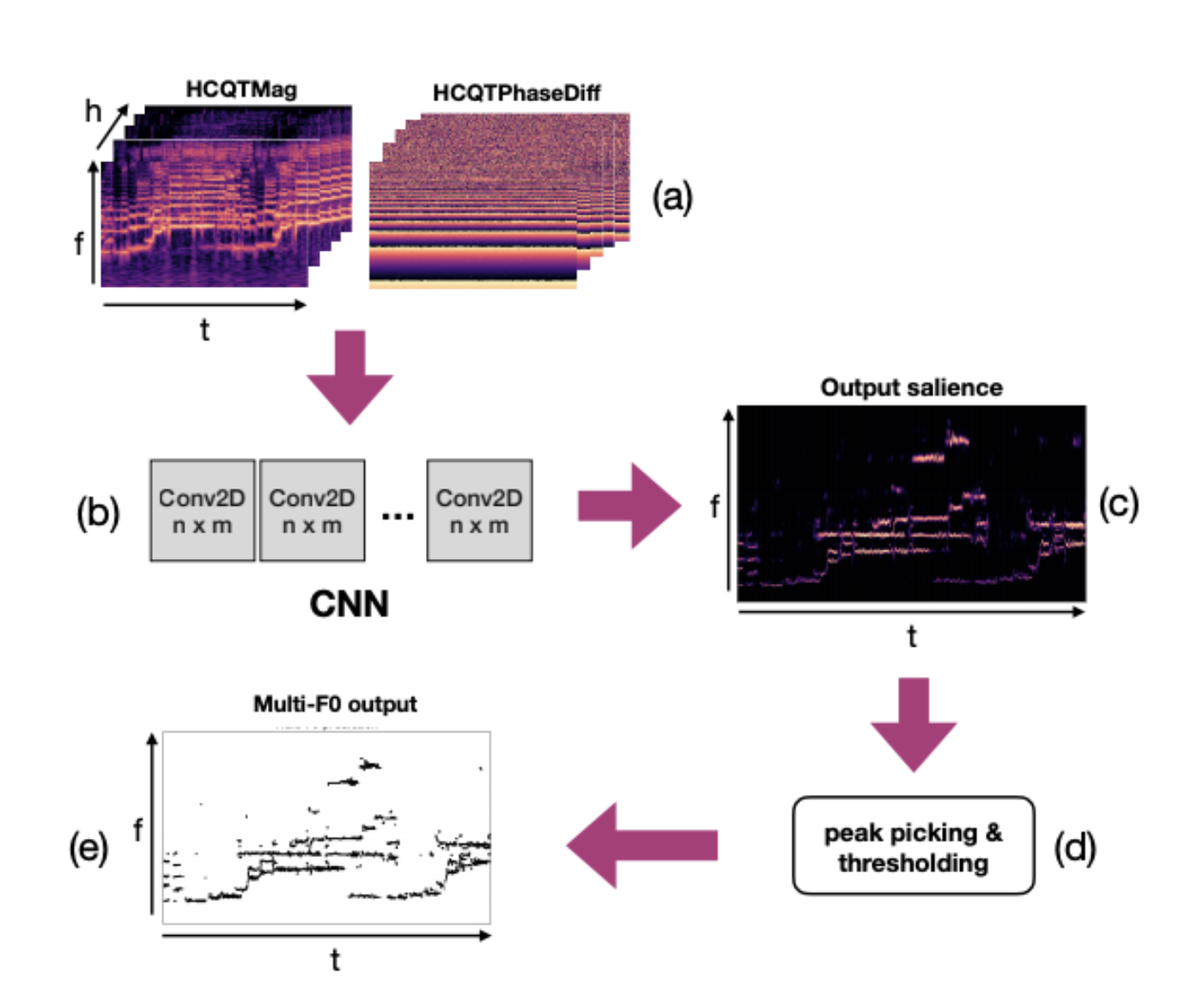
This work is a direct adaptation of CNNs on F0 estimation, applying on vocal ensembles. The key takeaways for me in this work is of 3-fold: (i) phase information does help for F0 estimation tasks (would it also be the same for other tasks? this will be interesting to explore); (ii) deeper models will work better; (iii) late concatenation of magnitude and phase information works better than early concatenation of both.
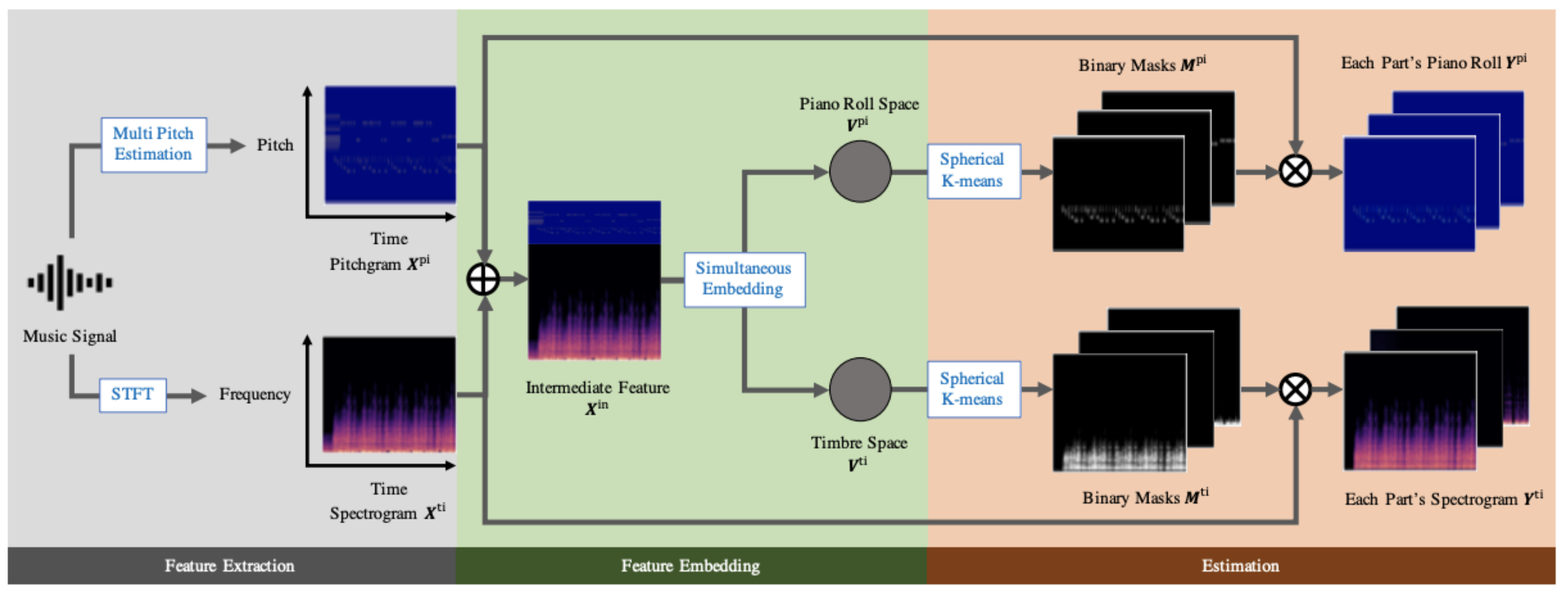
This is a super interesting work! For previous music transcription works, the output will be of a pre-defined set of instruments, with activation predicted for each instrument. This work intends to transcribe arbitrary instruments, hence being able to transcribe undefined instruments that are not included in the training data. The key idea is also inspired by methods from the speech domain, where deep clustering separates a speech mixture to an arbitrary number of speakers based on the characteristics of voices. Hence, the spectrograms and pitchgrams (estimated by an existing multi-pitch estimator) provide complementary information for timbre-based clustering and part separation.
Polyphonic Piano Transcription Using Autoregressive Multi-state Note Model
This work recognizes the problem of frame-level transcription: some frames might start after the onset events, which makes it harder to distinguish and transcribe. To solve this, the authors use an autoregressive model by utilizing the time-frequency and predicted transcription of the previous frame, and feeding them during the training of current step. Training of the autoregressive model is done via teacher-forcing. Results show that the model provides significantly higher accuracy on both note onset and offset estimation compared to its non-auto-regressive version. And just one thing to add: their demo is super excellent, such sleek and smooth visualization on real-time music transcription!
7 - Model Pruning
Ultra-light deep MIR by trimming lottery ticket
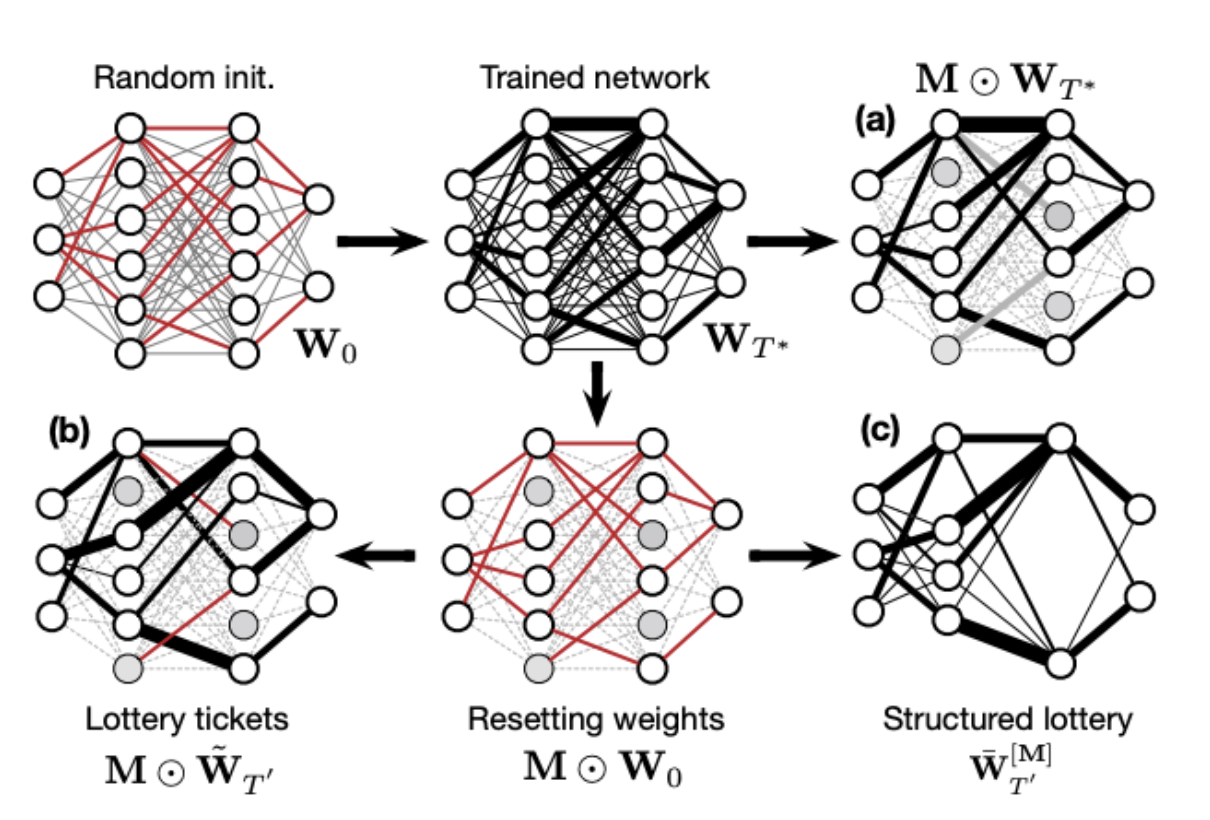
The lottery ticket hypothesis paper is the best paper in ICLR 2020, which motivates me to looking into this interesting work. Also, model compression is a really useful technique in an industrial setting as it significantly reduces memory footprint when scaling up to large-scale applications. With the new proposed approach by the authors known as structured trimming, which remove units based on magnitude, activation and normalization-based criteria, model size can be even more lighter without trading off much in terms of accuracy. The cool thing of this paper is that it evaluates the trimmed model on various popular MIR tasks, and these efficient trimmed subnetworks, removing up to 85% of the weights in deep models, could be found.
8 - Cover Song Detection
Combining musical features for cover detection
In previous cover song detection works, either the harmonic-related representation (e.g. HPCP, cremaPCP) or the melody-related representation (e.g. dominant melody, multi-pitch) is used. This work simply puts both together, and explores various fusion methods to inspect its improvement. The key intuition is that some cover songs are similar in harmonic content but not in dominant melody, and some are of the opposite. The interesting finding is that with only a simple average aggregation of \(d_\textrm{melody}\) and \(d_\textrm{cremaPCP}\), the model is able to yield the best improvement over individual models, and (strangely) it performs even better than a more sophisticated late fusion model.
Less is more: Faster and better music version identification with embedding distillation
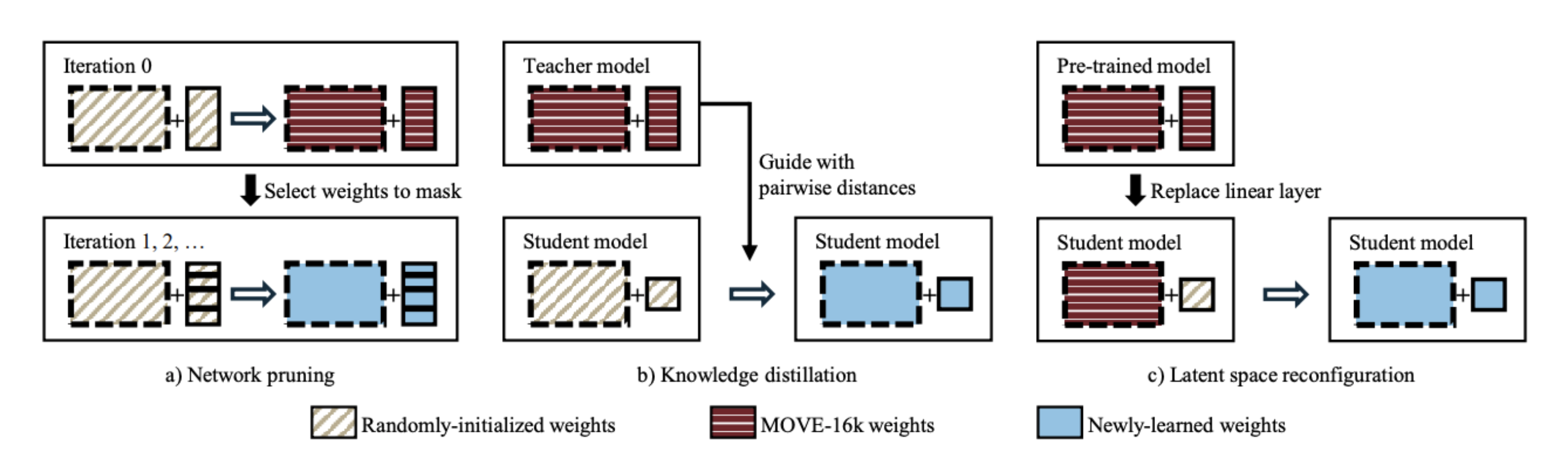
In a previous work, the authors proposed a musically-motivated embedding learning model for cover song detection, but the required embedding size is pretty huge at around 16,000. In this work, the authors experimented with various methods to reduce the amount of dimension in the embedding for large-scale retrieval applications. The results show that with a latent space reconfiguration method, which is very similar to transfer learning methods by fine-tuning additional dense layers on a pre-trained model, coupling with a normalized softmax loss, the model can achieve the best performance even under an embedding size of 256. Strangely, this performs better than training the whole network + dense layers from scratch.