
6 - Music Source Separation
Investigating U-Nets with various Intermediate Blocks for Spectrogram-based Singing Voice Separation
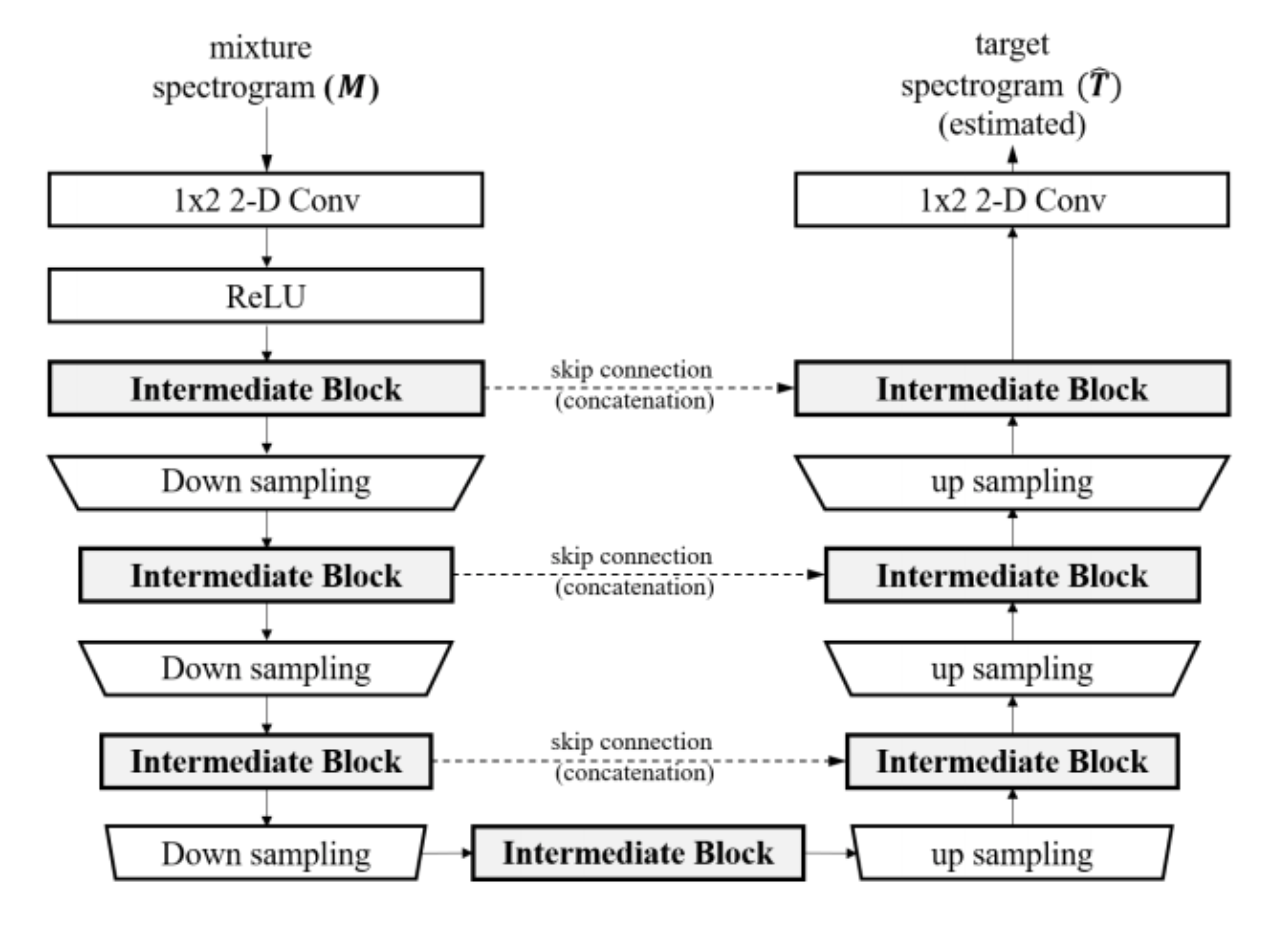
U-Nets are very common in singing voice separation, with their prior success in image segmentation. This work further inspects the usage of various intermediate blocks by providing comparison and evaluations. 2 types of intermediate blocks are used, Time-Distributed Blocks which does not have inter-frame operations, and Time-Frequency Blocks which considers both time and frequency domain. The variants of each block are inspected (fully connected, CNN, RNN etc.). The demo provided by this work is really superb - the best configuration found in this work yields a very clean singing voice separation.
Content based singing voice source separation via strong conditioning using aligned phonemes
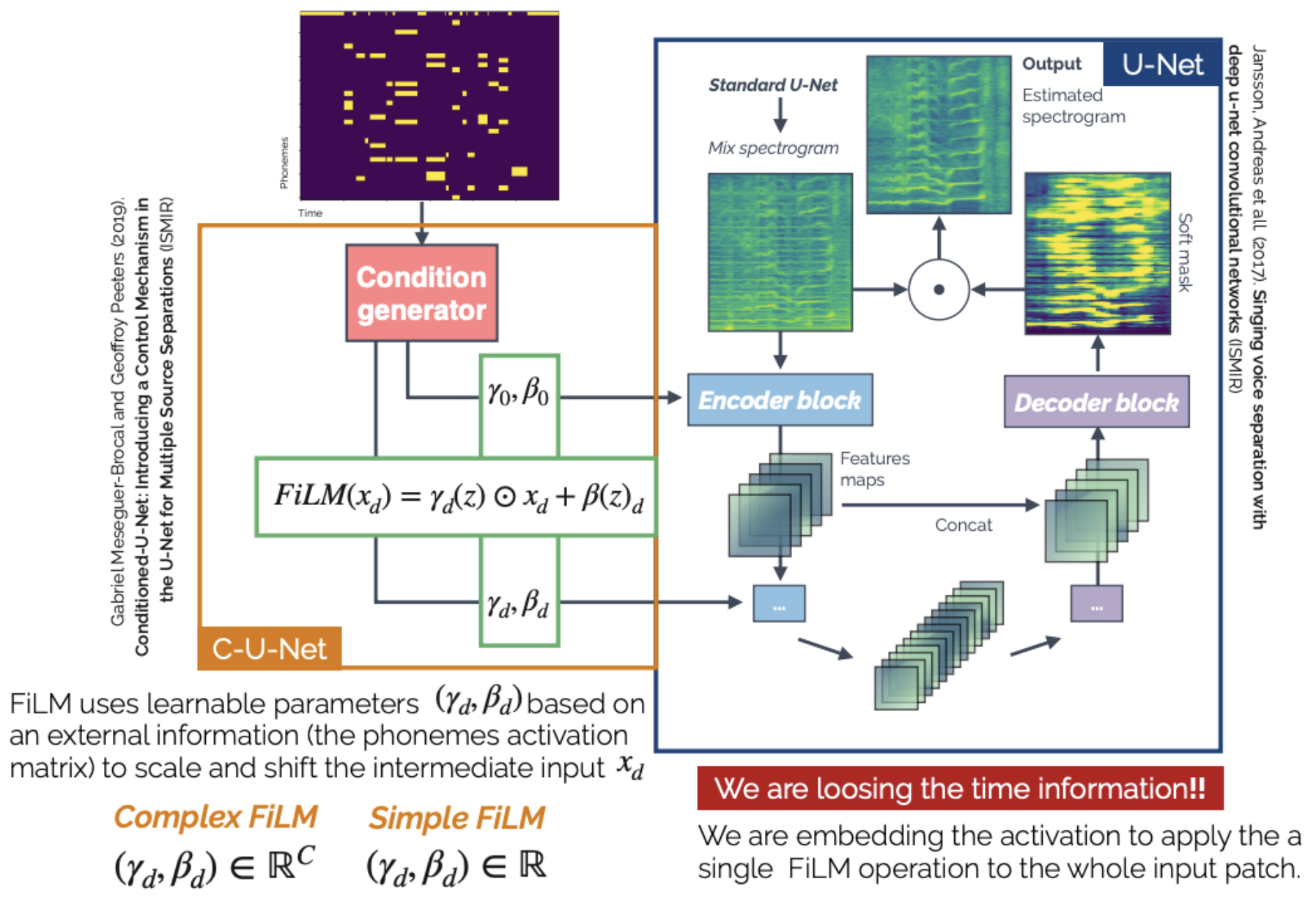
This work explores informed source separation - utilizing prior knowledge about the mixture and target source. In this work, the conditioning information used is lyrics, which are further aligned in the granularity of phonemes. This work uses the FiLM layer for conditioning, which the conditioning input is a 2D matrix of phonemes w.r.t. time. For weak conditioning, the same FiLM operation to the whole input patch; for strong conditioning, different FiLM operations are computed at different time frames.
Exploring Aligned Lyrics-informed Singing Voice Separation
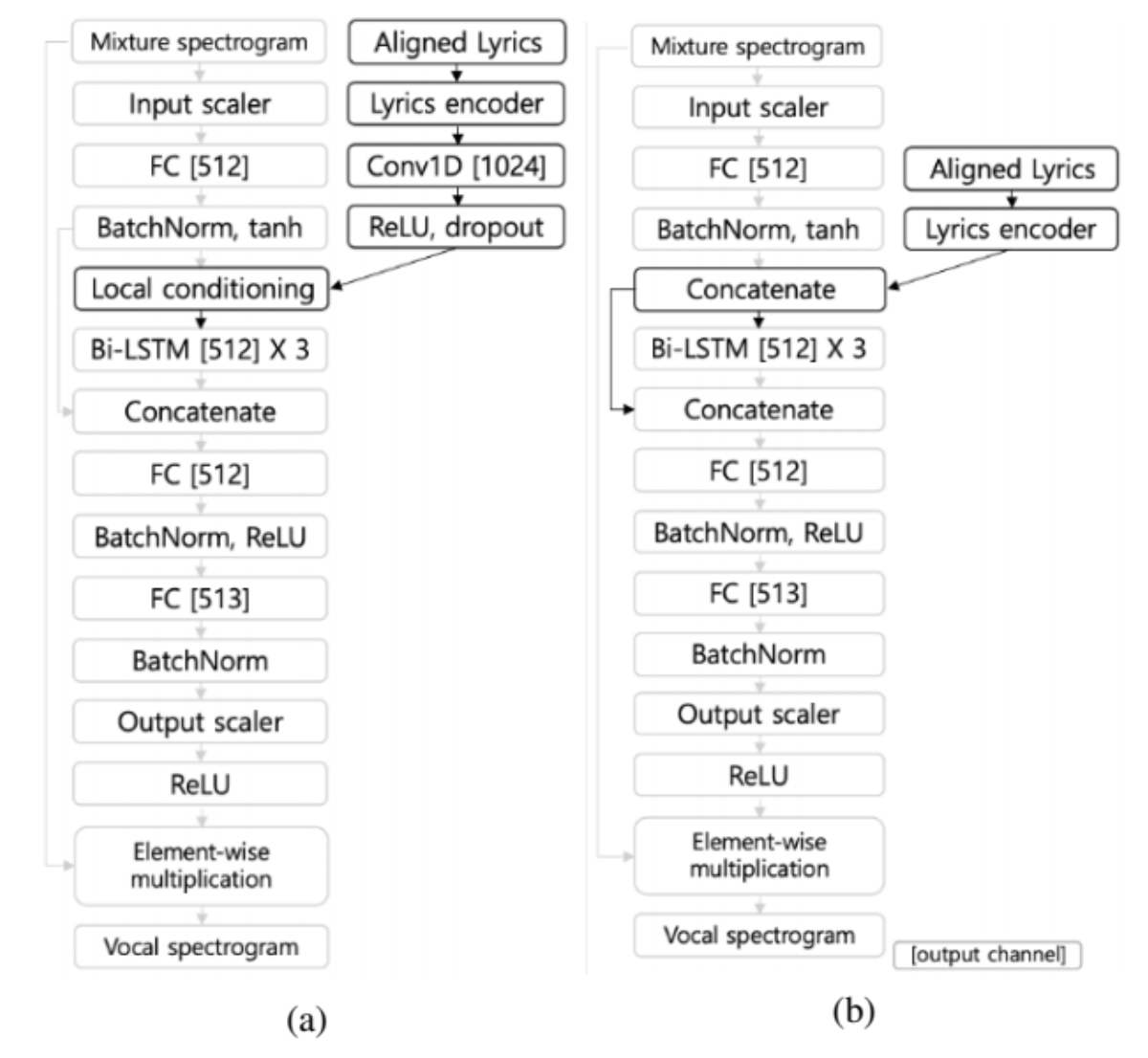
Similar to the above work, this work also utilizes aligned lyrics / phonemes for improving singing voice separation. The architecture is different - this work takes the backbone from the state-of-the-art Open Unmix model, then the authors propose to use an additional lyric encoder to learn embeddings for conditioning on the backbone. This idea resembles much with the idea from text-to-speech models, where the text information is encoded to condition on the speech synthesis component.
Multitask Learning for Instrument Activation Aware Music Source Separation
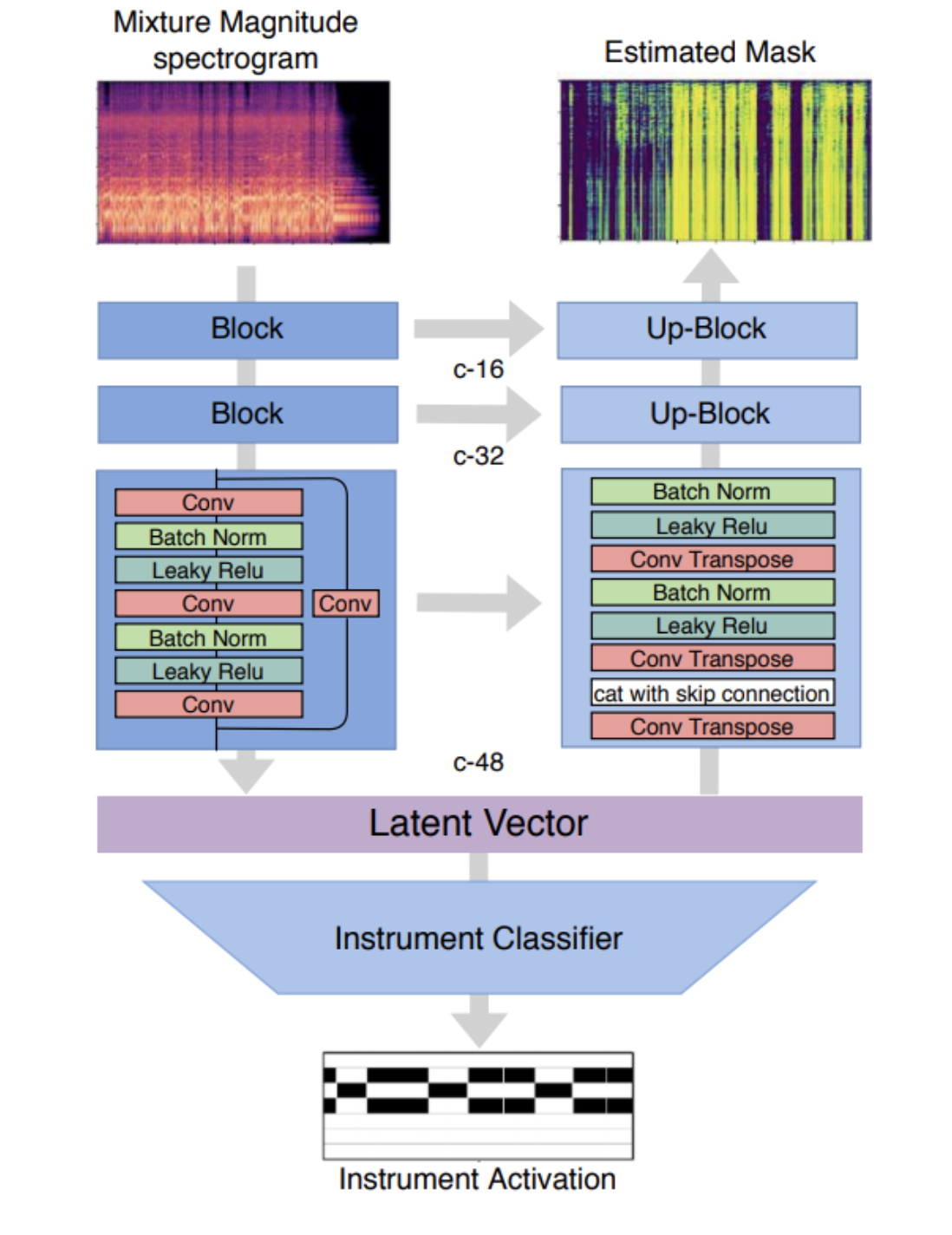
This work leverages multitask learning for source separation. Multitask learning states that by choosing a relevant subsidiary task, and allow it to train in line with the original task, can improve the performance of the original task. This work chooses to use instrument activation detection as the subsidary task, because it can intuitively suppress wrongly predicted activation by the source separation model at the supposed silent segments. By training on a larger dataset with multitask learning, the model can perform better on almost all aspects as compared to Open Unmix.
7 - Music Transcription / Pitch Estimation
Multiple F0 Estimation in Vocal Ensembles using Convolutional Neural Networks
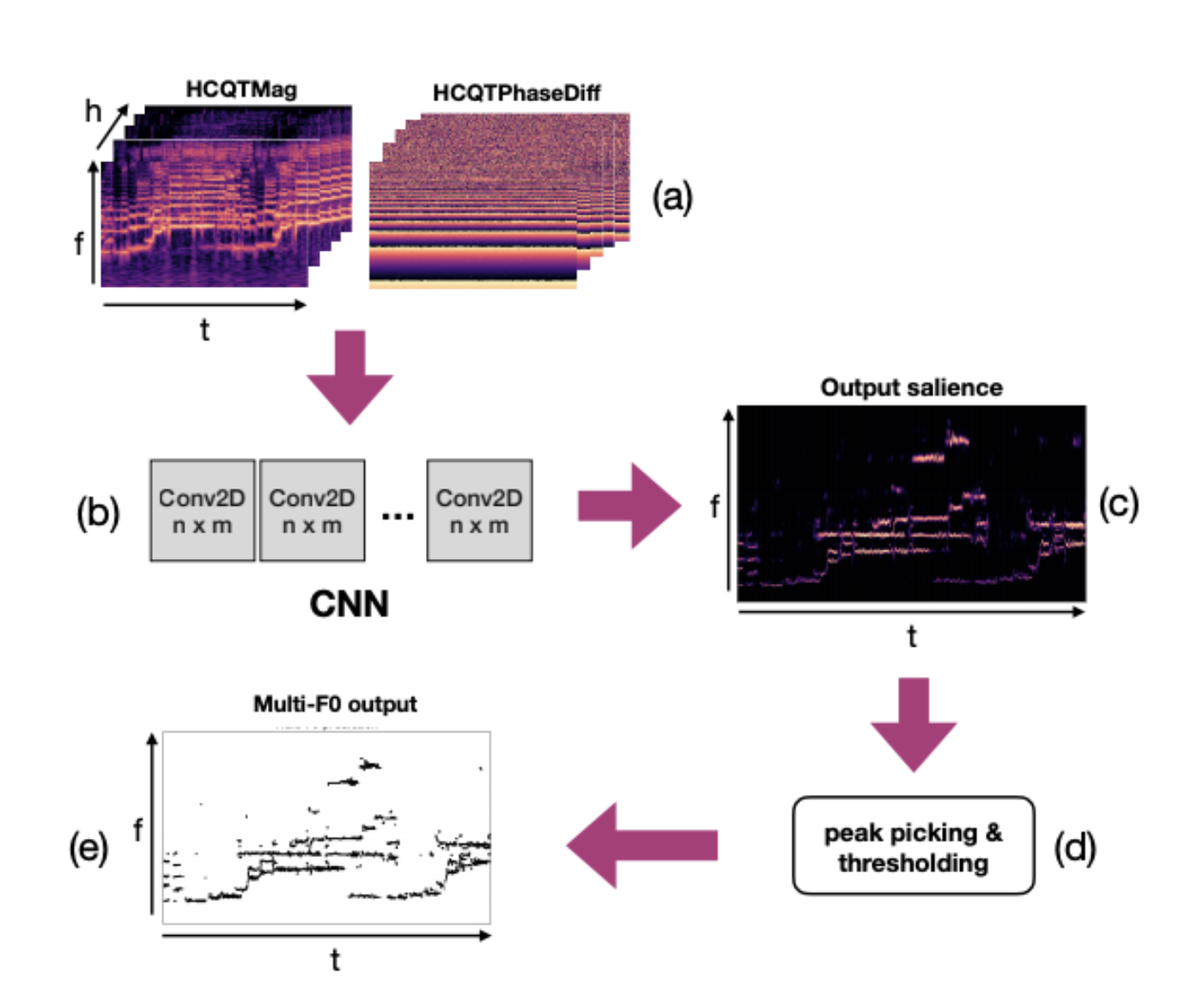
This work is a direct adaptation of CNNs on F0 estimation, applying on vocal ensembles. The key takeaways for me in this work is of 3-fold: (i) phase information does help for F0 estimation tasks (would it also be the same for other tasks? this will be interesting to explore); (ii) deeper models will work better; (iii) late concatenation of magnitude and phase information works better than early concatenation of both.
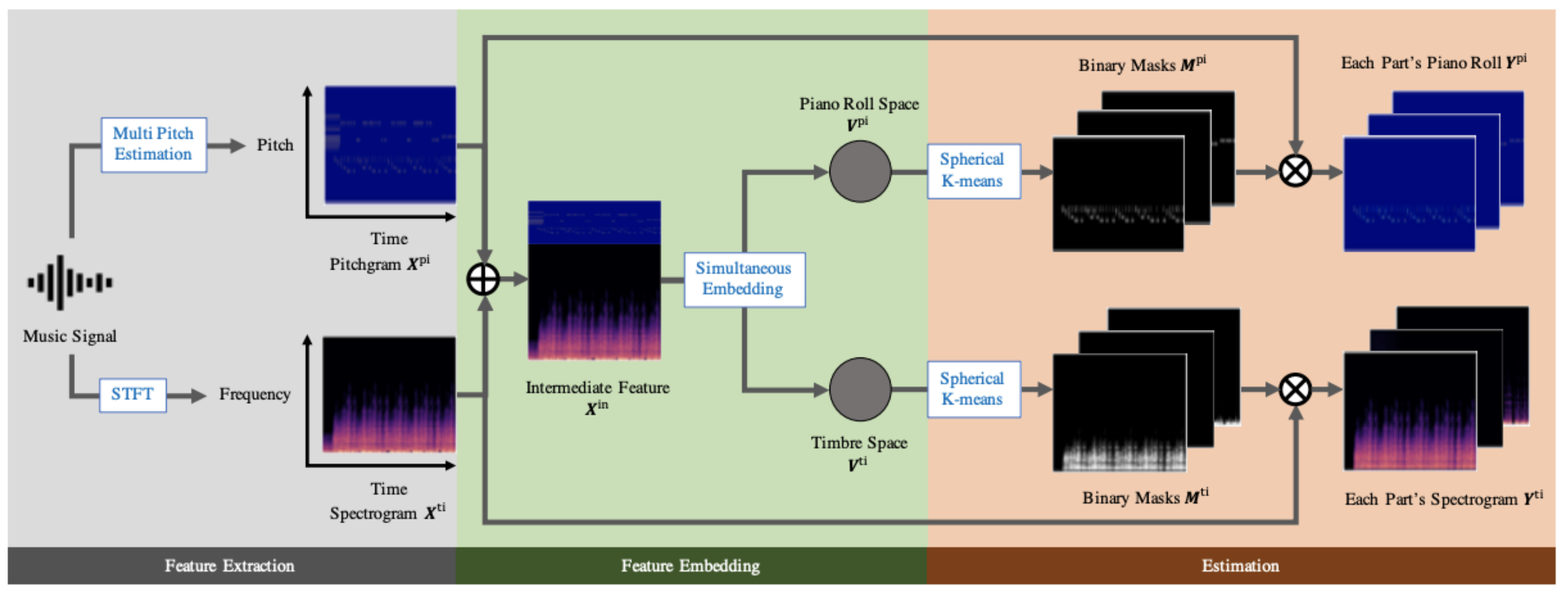
This is a super interesting work! For previous music transcription works, the output will be of a pre-defined set of instruments, with activation predicted for each instrument. This work intends to transcribe arbitrary instruments, hence being able to transcribe undefined instruments that are not included in the training data. The key idea is also inspired by methods from the speech domain, where deep clustering separates a speech mixture to an arbitrary number of speakers based on the characteristics of voices. Hence, the spectrograms and pitchgrams (estimated by an existing multi-pitch estimator) provide complementary information for timbre-based clustering and part separation.
Polyphonic Piano Transcription Using Autoregressive Multi-state Note Model
This work recognizes the problem of frame-level transcription: some frames might start after the onset events, which makes it harder to distinguish and transcribe. To solve this, the authors use an autoregressive model by utilizing the time-frequency and predicted transcription of the previous frame, and feeding them during the training of current step. Training of the autoregressive model is done via teacher-forcing. Results show that the model provides significantly higher accuracy on both note onset and offset estimation compared to its non-auto-regressive version. And just one thing to add: their demo is super excellent, such sleek and smooth visualization on real-time music transcription!
8 - Model Pruning
Ultra-light deep MIR by trimming lottery ticket
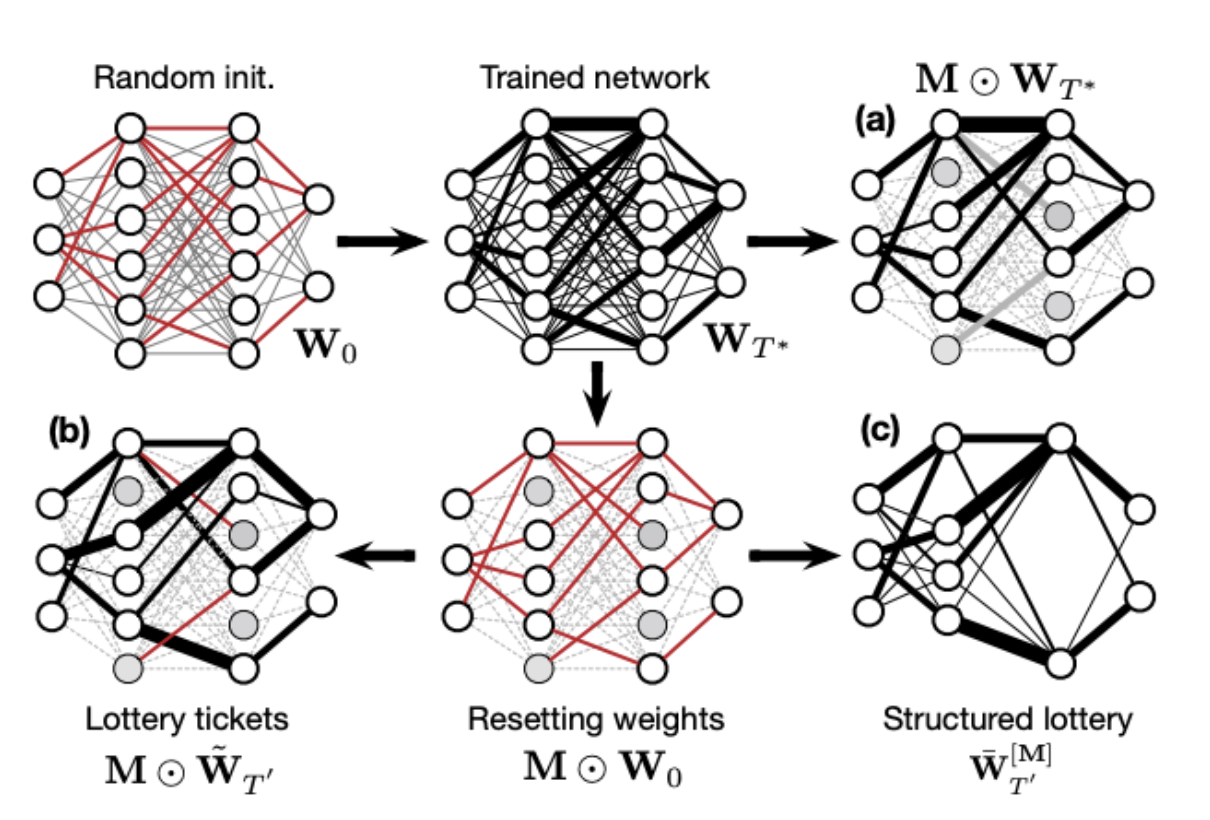
The lottery ticket hypothesis paper is the best paper in ICLR 2020, which motivates me to looking into this interesting work. Also, model compression is a really useful technique in an industrial setting as it significantly reduces memory footprint when scaling up to large-scale applications. With the new proposed approach by the authors known as structured trimming, which remove units based on magnitude, activation and normalization-based criteria, model size can be even more lighter without trading off much in terms of accuracy. The cool thing of this paper is that it evaluates the trimmed model on various popular MIR tasks, and these efficient trimmed subnetworks, removing up to 85% of the weights in deep models, could be found.
9 - Cover Song Detection
Combining musical features for cover detection
In previous cover song detection works, either the harmonic-related representation (e.g. HPCP, cremaPCP) or the melody-related representation (e.g. dominant melody, multi-pitch) is used. This work simply puts both together, and explores various fusion methods to inspect its improvement. The key intuition is that some cover songs are similar in harmonic content but not in dominant melody, and some are of the opposite. The interesting finding is that with only a simple average aggregation of \(d_\textrm{melody}\) and \(d_\textrm{cremaPCP}\), the model is able to yield the best improvement over individual models, and (strangely) it performs even better than a more sophisticated late fusion model.
Less is more: Faster and better music version identification with embedding distillation
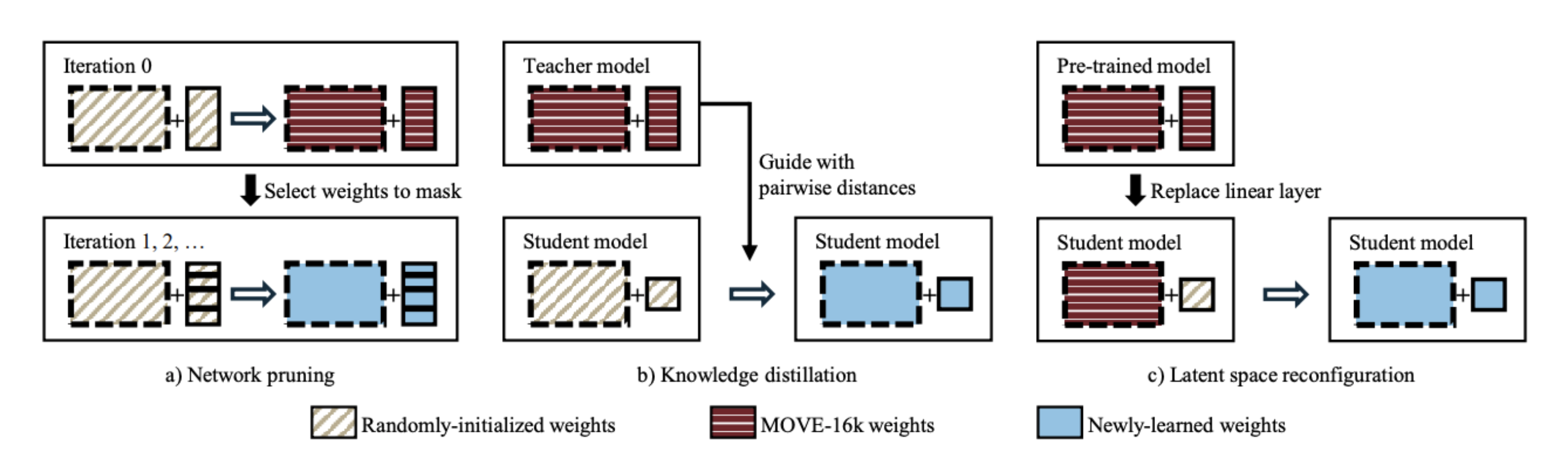
In a previous work, the authors proposed a musically-motivated embedding learning model for cover song detection, but the required embedding size is pretty huge at around 16,000. In this work, the authors experimented with various methods to reduce the amount of dimension in the embedding for large-scale retrieval applications. The results show that with a latent space reconfiguration method, which is very similar to transfer learning methods by fine-tuning additional dense layers on a pre-trained model, coupling with a normalized softmax loss, the model can achieve the best performance even under an embedding size of 256. Strangely, this performs better than training the whole network + dense layers from scratch.
10 - Last Words on ISMIR 2020
That’s all for my ISMIR 2020! I think the most magical moment for me would be when I could finally chat with some of the authors (and some are really big names!) of the works that I really like throughout my journey of MIR, and furthermore being able to exchange opinions with them. Just hope to be able to meet all of them physically some day!