
TLDR: This blog will discuss:
1 - Technical concepts in the RVC project
2 - Individual modules, such as VITS, RMVPE, HuBERT
3 - The top-k retrieval module, and how does it improve generation quality
Table of Contents
1 - Introduction2 - Architecture
3 - Deep Dive
3.1 - Content Feature Extraction
3.2 - Pitch Extraction
3.3 - Acoustic Model (VITS)
3.4 - Retrieval Module
4 - Inference
5 - Related Work
1 - Introduction
AI cover songs have taken the internet by storm alongside the recent generative AI boom ignited by ChatGPT. If you still haven’t had any experience on this piece of heavenly magic, have a listen to Fake Drake, AI Frank Sinatra, or Stephanie Sun (who later posted a gloomy response on the matter). To be honest, it’s weird to feel exciting and scary at the same time after listening to them.
In this blog post, I would like to provide a breakdown on (arguably) one of the most popular voice conversion project, which is the RVC project. I personally think that RVC is one of the reasons why AI covers have gained huge momentum, given that RVC provides a rather permissive license to use its source code and pretrained models, and an easy-to-use, beginner-friendly Web UI for fine-tuning.
I have come across many non-technical tutorials / videos about how to fine-tune RVC, but have yet to read an in-depth breakdown on the technical side of things, hence the motivation of writing this blog post. I will re-draw some of the diagrams based on my understanding, and (try to) justify the important steps in the RVC model.
Another thing to note is that, RVC shares a lot of common concepts with its “predecessor”, the So-VITS project, so I hope that this post provides enough details to help readers understand both projects. My crude understanding is that the main difference between So-VITS and RVC is the top-k retrieval module, so although the choices of some parts of the modules might be different, but the overall framework should stay similar.
2 - Architecture
Voice conversion is essentially a disentanglement task which aims to separate the content and the speaker information. Generally, a voice conversion model consists of a content encoder that extracts speaker-invariant content information (such as phonemes, text, intonation), and a acoustic model that reconstructs the target voice based on the given content.
We can break-down RVC into the following modules:
- A content feature extractor to extract information such as phonemes, intonation, etc. from the source audio. Here, RVC chooses HuBERT, or more precisely, a variant of ContentVec - this choice is similar to the early versions of So-VITS.
- A pitch extractor to get the coarse-level and fine-level F0 estimation. Pitch is an important part of the content information, especially in the context of singing voice. Here, RVC chooses RMVPE.
- A conditional acoustic model to generate the target audio based on given conditions (i.e. speaker ID & content information). Here, RVC chooses VITS as its generation framework, with some noticeble influence by HiFi-GAN on the vocoder - this choice is also largely inherited from So-VITS.
- A retrieval module newly introduced by RVC. Here, RVC stores all content features of the same speaker into a vector index, which can be used later for similarity search during inference. With this, since the content features are from the training set instead of being extracted solely from the source audio, it could introduce more information about the target speaker, further helping the reconstruction to sound more like the target speaker.
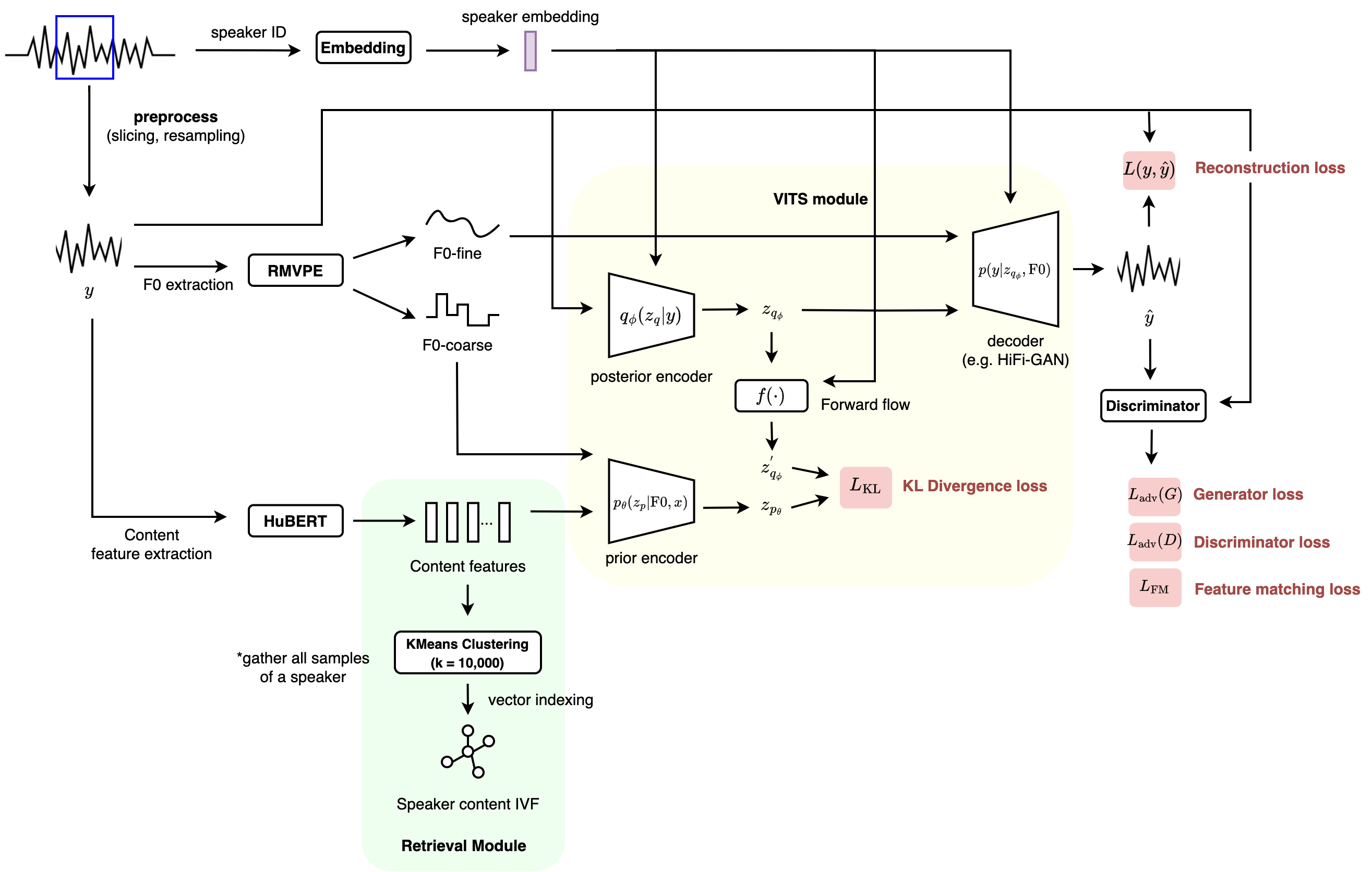
Figure 1: The architecture of RVC for training.
3.1 - Content Feature Extraction
HuBERT is one of the most popular self-supervised speech representation, commonly used in speech and audio related tasks. First, audio chunks are converted into a series of tokens via an offline clustering method (e.g. a K-Means clustering on the MFCCs over a large dataset). Then, some tokens within a sequence are masked, and a Transformer is trained to predict the masked tokens, i.e. the masked language modelling method (there is a reason why BERT appears in the name). The features learnt seems to help reduce word-error rate in speech recognition tasks, showing its superiority in encoding content-related information. The clustering / masked-language-modelling parts are sometimes called the teacher / student modules.
Both RVC and So-VITS uses the same hubert-base model, but despite its name, I don’t think it’s a purely pretrained HuBERT model, because from the ContentVec paper, it claims that HuBERT features could still achieve fairly good results on speaker identification, contradicting with the aim to disentangle speaker information. From the clues provided in So-VITS, I am more convinced that this “HuBERT” model has a higher resemblance with ContentVec (check out their video), which requires more steps to reduce the source speaker information. ContentVec is basically HuBERT, with a few speaker-invariant tweaks:
- During offline-clustering, before converting the audio into HuBERT features, the audio is randomly converted into other speaker’s voices;
- Add speaker-related transformation (e.g. formant transform) as augmentation when training the speech representation network, and impose a contrastive loss to enforce invariance in timbre changes;
- During masked label prediction, feed speaker info as condition to the student network to remove any need for further encoding speaker info.
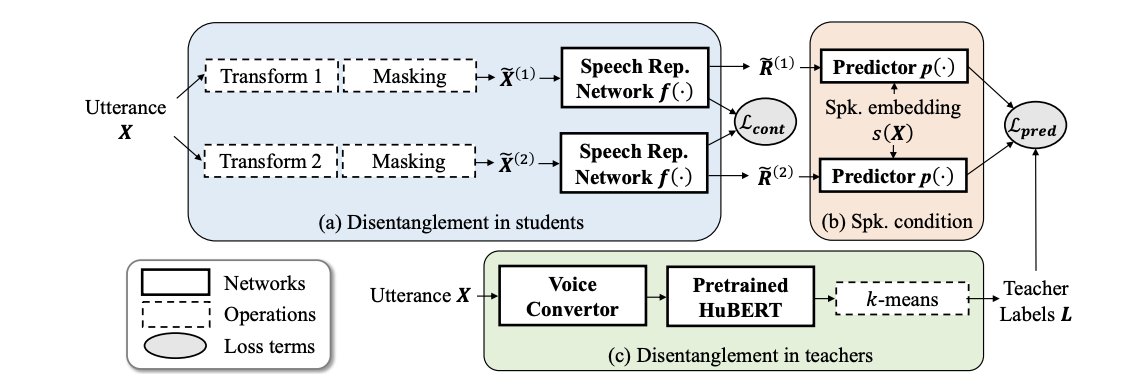
Figure 2: ContentVec training, diagram from the original paper.
3.2 - Pitch Extraction
Pitch (or more precisely, fundamental frequency) extraction is crucial for singing voice transfer. A popular pitch extractor used previously is crepe, which is a convolutional neural network trained in a supervised manner. RVC chooses a recent work called RMVPE, which is based on a U-Net like architecture. The key improvement is that RMVPE performs well even when the input audio is not a clean vocal track, so users can extract vocal pitch directly for polyphonic music, removing the need of running through a source separation model (probably the reason why the authors choose a U-Net). They also observe accuracy improvements over other pitch extraction models.
3.3 - Acoustic Model - VITS
The gist of RVC and So-VITS is their acoustic model, which is based on VITS. VITS is essentially a conditional VAE, augmented with normalizing flows and an adversarial training process. You can observe these 3 parts under the VITS module in Figure 1.
First, let’s frame the voice conversion problem as a conditional generation problem. Let \(p(y | c)\) denote the likelihood function that represents the voice conversion process, where \(y\) is the output audio and \(c\) is the content information condition (i.e. the HuBERT features and extracted pitch). We can approximate this intractable likelihood function by maximizing the following ELBO function, following the conditional VAE formulation:
$$E_{z\sim q(z|y)}[\log p(y|z, c)] - \mathcal{D}_{KL}(q(z|y) || p(z|c))$$
From here we need 3 neural networks to parameterize the posterior encoder \(q(z|y)\), the prior encoder \(p(z|c)\), and a decoder \(p(y|z, c)\). The first term in the ELBO is the reconstruction loss, and the second term is the KL loss between the posterior and prior distribution. This pretty much sums up the conditional VAE formulation.
To further improve on this, the authors find that increasing the expressiveness of the prior distribution is important for generating realistic samples. So, a normalizing (invertible) flow \(f_\theta\) is added to allow a transformation on the prior into a more complex distribution. Since the flow is invertible, during training the posterior is passed into the flow and compute the KL loss with the prior - this additional transform will help to bridge the “gap” between the posterior and the prior. Later during inference, the prior is passed into the inverse flow \(f^{-1}_{\theta}\) to map it to a more complex distribution for generation. This highly resembles the technique proposed in the variational inference with normalizing flows paper.
Lastly, as seen in most of the literature on high-fidelity singing voice synthesis or audio synthesis, a HiFi-GAN-style adversarial training is used on the decoder to improve generation quality. You can observe this technique used in e.g. DiffSinger, RAVE, Encodec, Stable Audio, etc. The adversarial training introduces a (multi-period) discriminator that tells if the generation is ground truth or generated output. A few losses are introduced:
- For the discriminator, to better distinguish ground truth / generated output: \(L_{\textrm{adv}}(D) = E_{y,z}((D(y) - 1)^2 + (D(G(z)))^2)\)
- For the generator (VITS decoder), to better “confuse” the discriminator: \(L_{\textrm{adv}}(G) = E_{z}(D(G(z) - 1)^2)\)
- Feature matching loss from Larsen et al., 2016, Kumar et al., 2019, which is essentially the L1 loss of the discriminator’s intermediate states, when taking \(y\) and \(G(z)\) as input respectively: \(L_{\textrm{FM}}(G) = E_{y,z}(\sum_{l} ||D_l(y) - D_l(G(z))||_1)\)
A little more about the decoder used (or more commonly known as vocoder here), it is the NSF-HiFiGAN from DiffSinger. Instead of using mel-spectrogram as input like HiFi-GAN, NSF (neural source-filter) takes in the learnt “spectral” features \(z\) and F0. The F0 is used to generate the excitation signal using a harmonic + noise source module. After that, the excitation signal and \(z\) are passed through the neural filter module, which consists of a series of convolutional layers and residual blocks across several upsampling resolutions, to “filter” the excitation signal in order to obtain the output audio. For the detailed implementation, kindly refer to the source code here.
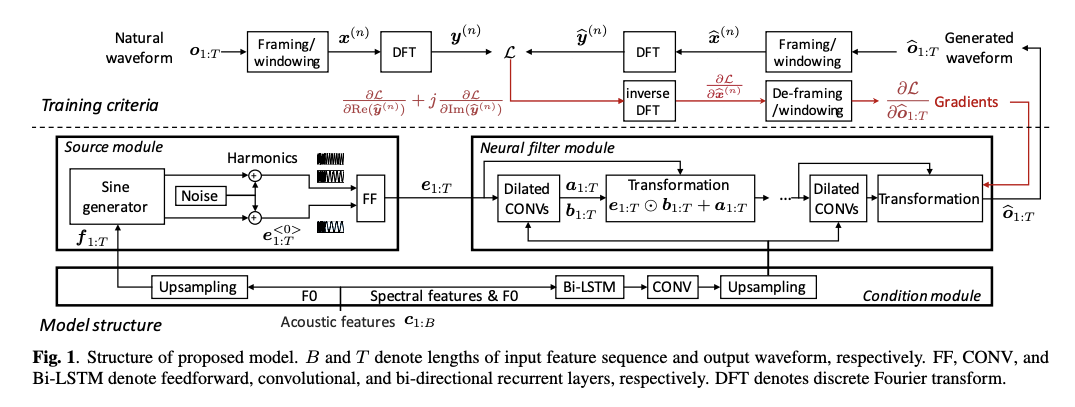
Figure 3: Neural source filter model, diagram from ths NSF paper. (exact details might differ from DiffSinger's implementation)
One more point to add is that, RVC chooses to use the coarse version of F0 (which is basically being discretized into a fixed range of integers) in the prior encoder, instead of the continuous-value fine-grain F0. I suppose the reason might be that the discretized “F0 tokens” are much easier to be used together with the HuBERT features, in this case, the discretized F0s are passed through an embedding layer and added to a projection of the HuBERT features, hence obtaining the condition signal for the prior encoder (see the source code here).
3.4 - Retrieval Module
The above sections should cover most of the high-level details in So-VITS. So, what’s new in RVC? The key idea is to store the ContentVec features for each speaker during training, hoping that they can be reused during inference, to add more target-speaker-related information in the generation pipeline. The aim is to generate output audio that could capture more detailed timbre and nuances of the target speaker, and reduce timbre leakage from the source speaker.
To do this, we need to store a vector index for each speaker. During training, all HuBERT feature vectors corresponding to the same speaker are saved. As later during inference, we want to be able to quickly search for the nearest vectors, given the HuBERT feature vectors from the source audio, so that we can either (i) use these nearest vectors as substitutes, or (ii) fuse them linearly with the source feature vectors. Therefore, we need to store a vector index to facilitate approximate nearest neighbour (ANN) search. Here RVC chooses to store an inverted index file (IVF), which first requires partitioning the vectors (e.g. through clustering), and then create an index that maps each cluster (centroid) to the data points (vectors) that belong to that cluster. During ANN search, we first identify the cluster centroid, and only searches the vectors in the cluster - this normally gives us a good enough approximate candidate. ANN is a super interesting topic - kindly refer to faiss‘s wiki if you are interested in other advanced indexing and search techniques, such as the popular IVF-PQ and HNSW for large-scale vector search.
4 - Inference
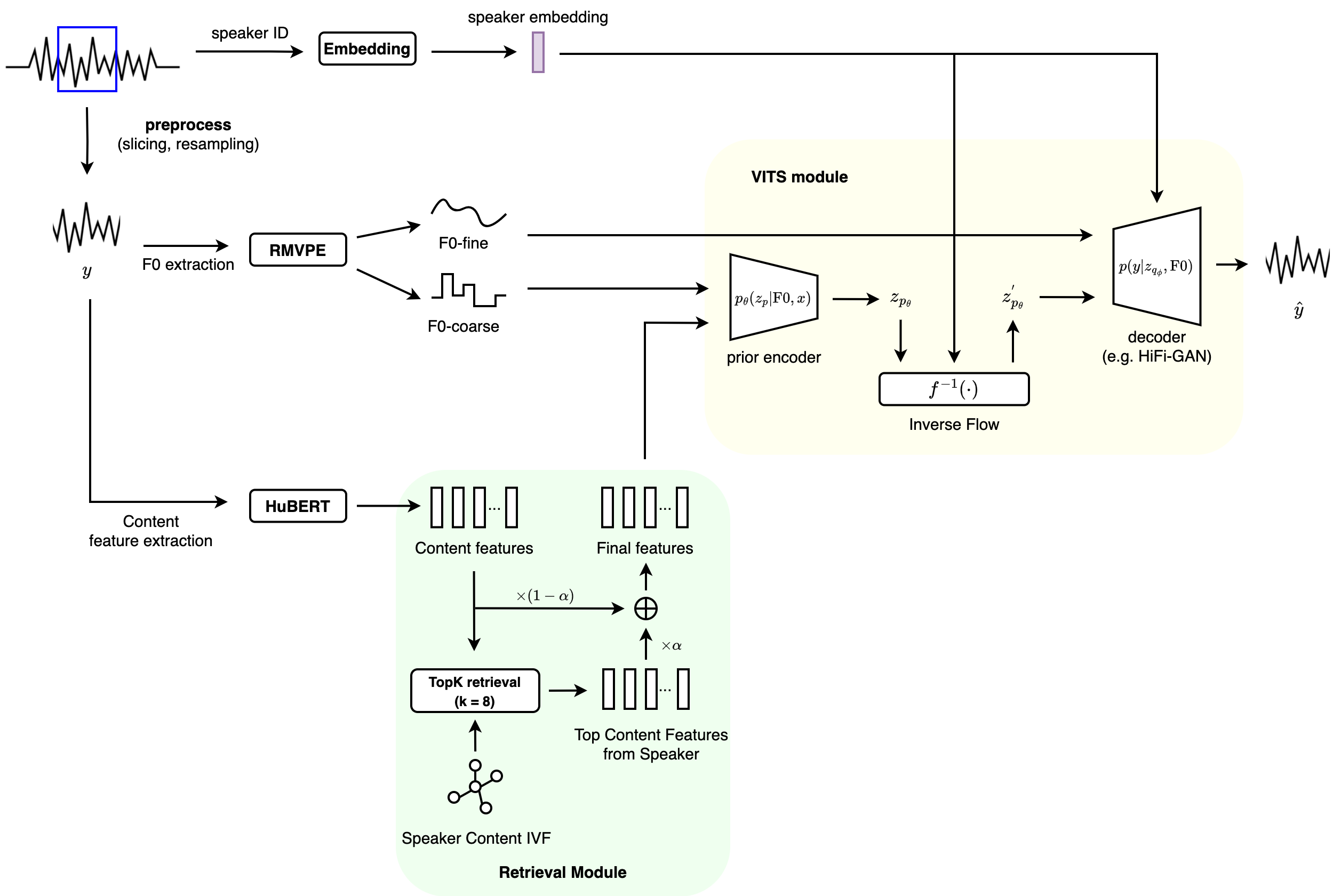
Figure 2: RVC for inference.
For inference, let’s first discuss the retrieval module. Given the source HuBERT feature vectors and a selected target speaker, we search for top-\(K\) vectors that are most similar to the source vectors (RVC chooses \(K = 8\)) from the vector index. RVC also introduces an index_rate parameter, \(\alpha\), which decides how much of the target speaker feature vectors should be linearly fused with the source vectors (refer to Figure 2). The intuition here is that, although ContentVec is supposed to output speaker-invariant source feature vectors, in practice it might still have some source speaker-related information, so swapping it out with the target speaker features should better reduce the “timbre leak” from the source speaker. You can refer to the authors’ notes on how to tune the index rate - in most of the cases in RVC \(\alpha = 0.3\).
The rest of the inference part in the VITS module is straightforward - a latent variable \(z_p\) is sampled from the prior encoder, which is conditioned on F0 and the (swapped) HuBERT features. As discussed, \(z_p\) is passed through an inverse flow \(f^{-1}\) to increase its distribution complexity, and it is fed into the NSF-HiFiGAN vocoder, together with the F0, to generate the output.
5 - Related Work
It’s truly an exciting time for singing voice conversion. First, there is a singing voice conversion challenge last year, and you can observe various new systems proposed with innovations on different content feature extractor, pitch extractor, and vocoder. Diffusion models, such as DiffSVC, are a popular choice recently, which formulates the conversion task as a denoising task using denoising diffusion probabilitic models (DDPM), conditioned by content features, F0s and loudness. To further speed up the inference speed, which is a commonly known issue for DDPMs, there is already a recent work that uses consistency models. There are also various attempts to make SVC fast and resource-efficient: Nercessian et al. 2023 runs SVC as a plugin in real-time, FastSVC achieves for a real-time factor of ~0.25 (1min to convert 4min of singing) on CPUs.
For a quick summary of the recent singing voice conversion methods, I recommend you to check out this awesome article by Naotake Masuda from Neutone. Also, check out a comparative study paper on the systems submitted to the recent singing voice conversion challenge.
6 - Code Implementation
Sharing a few code portals that point to the important modules in RVC:
- Pitch extraction
- Content feature extraction
- VITS module
- NSF-HiFiGAN vocoder
- Retrieval module indexing and ANN retrieval